redis官网
https://redis.io/docs/reference/
redis命令
https://redis.io/commands/unlink/
redis数据类型和结构
ziplist(压缩列表)
http://zhangtielei.com/posts/blog-redis-ziplist.html
ziplist是一个经过特殊编码的双向链表,它的设计目标就是为了提高存储效率。ziplist可以用于存储字符串或整数,其中整数是按真正的二进制表示进行编码的,而不是编码成字符串序列。
它能以O(1)的时间复杂度在表的两端提供push和pop操作。
实际上,ziplist充分体现了Redis对于存储效率的追求。
一个普通的双向链表,链表中每一项都占用独立的一块内存,各项之间用地址指针(或引用)连接起来。这种方式会带来大量的内存碎片,而且地址指针也会占用额外的内存。
而ziplist却是将表中每一项存放在前后连续的地址空间内,一个ziplist整体占用一大块内存。它是一个表(list),但其实不是一个链表(linked list)。
ziplist的数据结构定义
ziplist的数据结构组成是本文要讨论的重点。实际上,ziplist还是稍微有点复杂的,它复杂的地方就在于它的数据结构定义。一旦理解了数据结构,它的一些操作也就比较容易理解了。
我们接下来先从总体上介绍一下ziplist的数据结构定义,然后举一个实际的例子,通过例子来解释ziplist的构成。如果你看懂了这一部分,本文的任务就算完成了一大半了。
从宏观上看,ziplist的内存结构如下:
<zlbytes><zltail><zllen><entry>...<entry><zlend>
各个部分在内存上是前后相邻的,它们分别的含义如下:
<zlbytes>: 32bit,表示ziplist占用的字节总数(也包括<zlbytes>本身占用的4个字节)。<zltail>: 32bit,表示ziplist表中最后一项(entry)在ziplist中的偏移字节数。<zltail>的存在,使得我们可以很方便地找到最后一项(不用遍历整个ziplist),从而可以在ziplist尾端快速地执行push或pop操作。<zllen>: 16bit, 表示ziplist中数据项(entry)的个数。zllen字段因为只有16bit,所以可以表达的最大值为216-1。这里需要特别注意的是,如果ziplist中数据项个数超过了16bit能表达的最大值,ziplist仍然可以来表示。那怎么表示呢?这里做了这样的规定:如果`<zllen>`小于等于216-2(也就是不等于2^16-1),那么<zllen>就表示ziplist中数据项的个数;否则,也就是<zllen>等于16bit全为1的情况,那么<zllen>就不表示数据项个数了,这时候要想知道ziplist中数据项总数,那么必须对ziplist从头到尾遍历各个数据项,才能计数出来。<entry>: 表示真正存放数据的数据项,长度不定。一个数据项(entry)也有它自己的内部结构,这个稍后再解释。<zlend>: ziplist最后1个字节,是一个结束标记,值固定等于255。
上面的定义中还值得注意的一点是:<zlbytes>, <zltail>, <zllen>既然占据多个字节,那么在存储的时候就有大端(big endian)和小端(little endian)的区别。ziplist采取的是小端模式来存储,这在下面我们介绍具体例子的时候还会再详细解释。
我们再来看一下每一个数据项<entry>的构成:
<prevrawlen><len><data>
我们看到在真正的数据(<data>)前面,还有两个字段:
<prevrawlen>: 表示前一个数据项占用的总字节数。这个字段的用处是为了让ziplist能够从后向前遍历(从后一项的位置,只需向前偏移prevrawlen个字节,就找到了前一项)。这个字段采用变长编码。<len>: 表示当前数据项的数据长度(即<data>部分的长度)。也采用变长编码。
好了,ziplist的数据结构定义,我们介绍完了,现在我们看一个具体的例子。
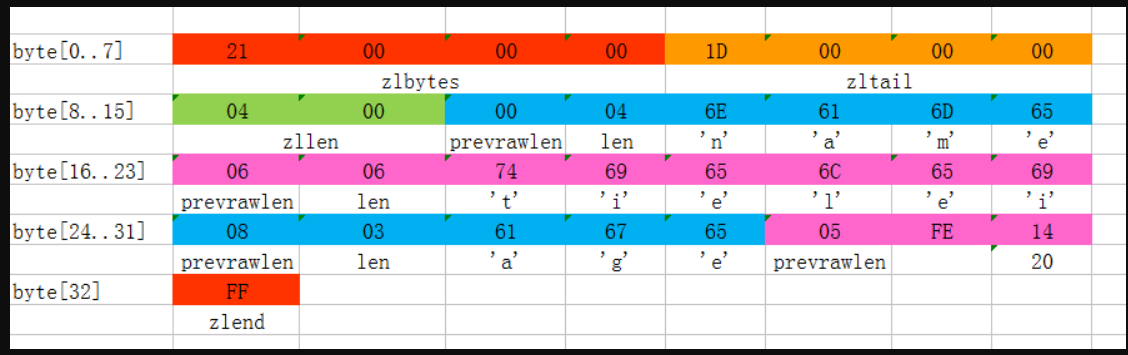
上图是一份真实的ziplist数据。我们逐项解读一下:
- 这个ziplist一共包含33个字节。字节编号从byte[0]到byte[32]。图中每个字节的值使用16进制表示。
- 头4个字节(0x21000000)是按小端(little endian)模式存储的
<zlbytes>字段。什么是小端呢?就是指数据的低字节保存在内存的低地址中(参见维基百科词条Endianness)。因此,这里<zlbytes>的值应该解析成0x00000021,用十进制表示正好就是33。 - 接下来4个字节(byte[4…7])是
<zltail>,用小端存储模式来解释,它的值是0x0000001D(值为29),表示最后一个数据项在byte[29]的位置(那个数据项为0x05FE14)。 - 再接下来2个字节(byte[8…9]),值为0x0004,表示这个ziplist里一共存有4项数据。
- 接下来6个字节(byte[10…15])是第1个数据项。其中,prevrawlen=0,因为它前面没有数据项;len=4,相当于前面定义的9种情况中的第1种,表示后面4个字节按字符串存储数据,数据的值为”name”。
- 接下来8个字节(byte[16…23])是第2个数据项,与前面数据项存储格式类似,存储1个字符串”tielei”。
- 接下来5个字节(byte[24…28])是第3个数据项,与前面数据项存储格式类似,存储1个字符串”age”。
- 接下来3个字节(byte[29…31])是最后一个数据项,它的格式与前面的数据项存储格式不太一样。其中,第1个字节prevrawlen=5,表示前一个数据项占用5个字节;第2个字节=FE,相当于前面定义的9种情况中的第8种,所以后面还有1个字节用来表示真正的数据,并且以整数表示。它的值是20(0x14)。
- 最后1个字节(byte[32])表示
<zlend>,是固定的值255(0xFF)。
总结一下,这个ziplist里存了4个数据项,分别为:
- 字符串: “name”
- 字符串: “tielei”
- 字符串: “age”
- 整数: 20
quicklist(快速列表)
http://zhangtielei.com/posts/blog-redis-quicklist.html
quicklist概述
Redis对外暴露的上层list数据类型,经常被用作队列使用。比如它支持的如下一些操作:
lpush: 在左侧(即列表头部)插入数据。rpop: 在右侧(即列表尾部)删除数据。rpush: 在右侧(即列表尾部)插入数据。lpop: 在左侧(即列表头部)删除数据。
这些操作都是O(1)时间复杂度的。
当然,list也支持在任意中间位置的存取操作,比如lindex和linsert,但它们都需要对list进行遍历,所以时间复杂度较高,为O(N)。
概况起来,list具有这样的一些特点:它是一个能维持数据项先后顺序的列表(各个数据项的先后顺序由插入位置决定),便于在表的两端追加和删除数据,而对于中间位置的存取具有O(N)的时间复杂度。这不正是一个双向链表所具有的特点吗?
list的内部实现quicklist正是一个双向链表。在quicklist.c的文件头部注释中,是这样描述quicklist的:
quicklist确实是一个双向链表,而且是,每一个元素都是一个ziplist 的双向链表。
我们知道,双向链表是由多个节点(Node)组成的。这个描述的意思是:quicklist的每个节点都是一个ziplist。ziplist我们已经在上一篇介绍过。
ziplist本身也是一个能维持数据项先后顺序的列表(按插入位置),而且是一个内存紧缩的列表(各个数据项在内存上前后相邻)。比如,一个包含3个节点的quicklist,如果每个节点的ziplist又包含4个数据项,那么对外表现上,这个list就总共包含12个数据项。
quicklist的结构为什么这样设计呢?总结起来,大概又是一个空间和时间的折中:
- 双向链表便于在表的两端进行push和pop操作,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
- ziplist由于是一整块连续内存,所以存储效率很高。但是,它不利于修改操作,每次数据变动都会引发一次内存的realloc。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝,进一步降低性能。
于是,结合了双向链表和ziplist的优点,quicklist就应运而生了。
quicklist的结构图举例:
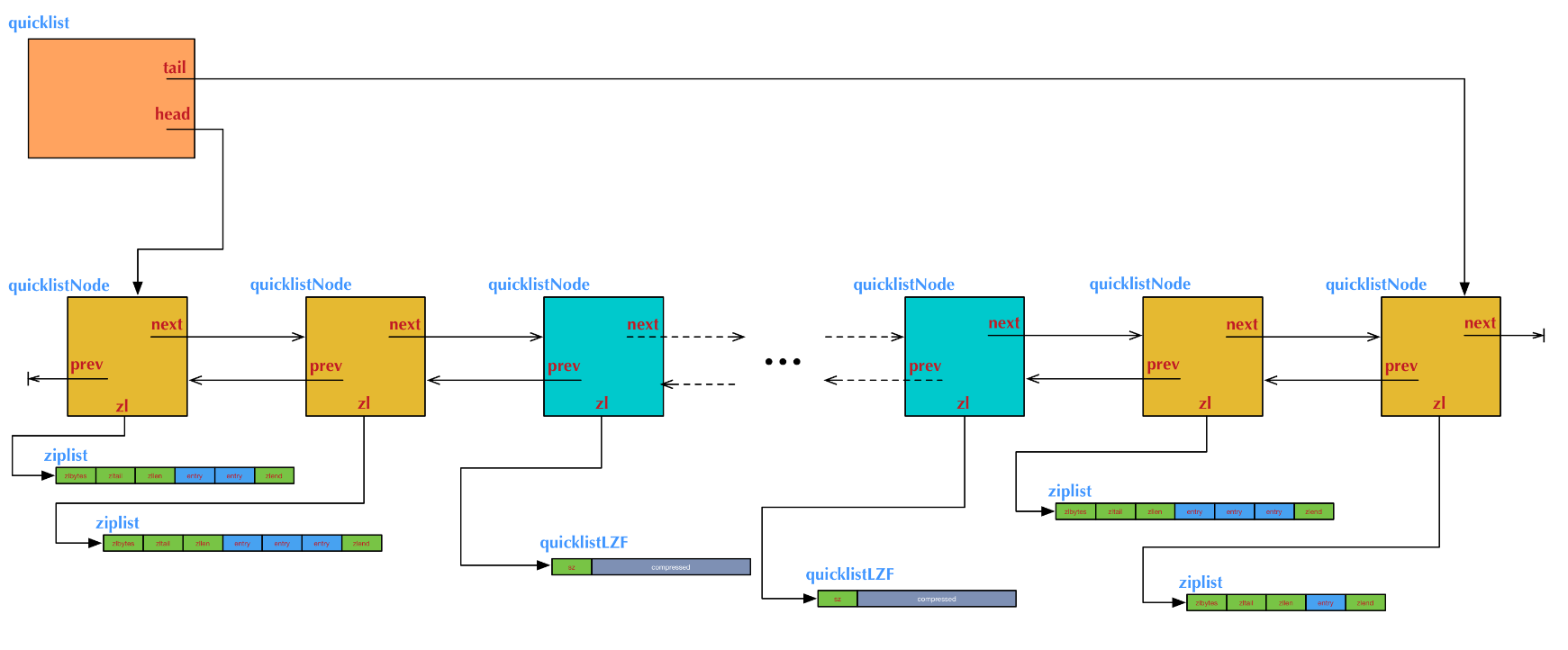
不过,这也带来了一个新问题:到底一个quicklist节点包含多长的ziplist合适呢?比如,同样是存储12个数据项,既可以是一个quicklist包含3个节点,而每个节点的ziplist又包含4个数据项,也可以是一个quicklist包含6个节点,而每个节点的ziplist又包含2个数据项。
这又是一个需要找平衡点的难题。我们只从存储效率上分析一下:
- 每个quicklist节点上的ziplist越短,则内存碎片越多。内存碎片多了,有可能在内存中产生很多无法被利用的小碎片,从而降低存储效率。这种情况的极端是每个quicklist节点上的ziplist只包含一个数据项,这就蜕化成一个普通的双向链表了。
- 每个quicklist节点上的ziplist越长,则为ziplist分配大块连续内存空间的难度就越大。有可能出现内存里有很多小块的空闲空间(它们加起来很多),但却找不到一块足够大的空闲空间分配给ziplist的情况。这同样会降低存储效率。这种情况的极端是整个quicklist只有一个节点,所有的数据项都分配在这仅有的一个节点的ziplist里面。这其实蜕化成一个ziplist了。
可见,一个quicklist节点上的ziplist要保持一个合理的长度。那到底多长合理呢?这可能取决于具体应用场景。实际上,Redis提供了一个配置参数list-max-ziplist-size,就是为了让使用者可以来根据自己的情况进行调整。
list-max-ziplist-size -2
redis Key &value 存储
http://redisbook.com/index.html
Redis 服务器在初始化时,默认的会预先分配 16 个数据库。这其中的每一个数据库,都由一个 redisDb 的结构存储。redisDb 的结构中有两个重要的部分:
redisDb.id:存储着 redis 数据库以整数表示的号码。
redisDb.dict:存储着该库所有的键值对数据。
redisDb.expires:保存着每一个键的过期时间。
针对 Redis 中的众多数据库,当我们使用 select number 选择数据库时,程序可以直接通过 redisServer.db[number] 来切换数据库。有时候当程序需要知道自己是在哪个数据库时,也可以直接通过读取 redisDb.id 即可。
Redis 的字典使用哈希表作为其底层实现。dict 类型使用的两个指向哈希表的指针,其中 0 号哈希表(ht[0])主要用于存储数据库的所有键值,而 1 号哈希表主要用于程序对 0 号哈希表进行 rehash 时使用,rehash 一般是在添加新值时会触发,这里不做过多的赘述。
所以 redis 中查找一个 key,其实就是对进行该 dict 结构中的 ht[0] 进行查找操作。
Redis 是一个键值对(key-value pair)数据库服务器, 服务器中的每个数据库都由一个 redis.h/redisDb 结构表示, 其中, redisDb 结构的 dict 字典保存了数据库中的所有键值对, 我们将这个字典称为键空间(key space):
typedef struct redisDb {
// ...
// 数据库键空间,保存着数据库中的所有键值对
dict *dict;
// ...
} redisDb;
键空间和用户所见的数据库是直接对应的:
- 键空间的键也就是数据库的键, 每个键都是一个字符串对象。
- 键空间的值也就是数据库的值, 每个值可以是字符串对象、列表对象、哈希表对象、集合对象和有序集合对象在内的任意一种 Redis 对象。
举个例子, 如果我们在空白的数据库中执行以下命令:
redis> SET message "hello world"
OK
redis> RPUSH alphabet "a" "b" "c"
(integer) 3
redis> HSET book name "Redis in Action"
(integer) 1
redis> HSET book author "Josiah L. Carlson"
(integer) 1
redis> HSET book publisher "Manning"
(integer) 1
那么在这些命令执行之后, 数据库的键空间将会是图 IMAGE_DB_EXAMPLE 所展示的样子:
alphabet是一个列表键, 键的名字是一个包含字符串"alphabet"的字符串对象, 键的值则是一个包含三个元素的列表对象。book是一个哈希表键, 键的名字是一个包含字符串"book"的字符串对象, 键的值则是一个包含三个键值对的哈希表对象。message是一个字符串键, 键的名字是一个包含字符串"message"的字符串对象, 键的值则是一个包含字符串"hello world"的字符串对象。
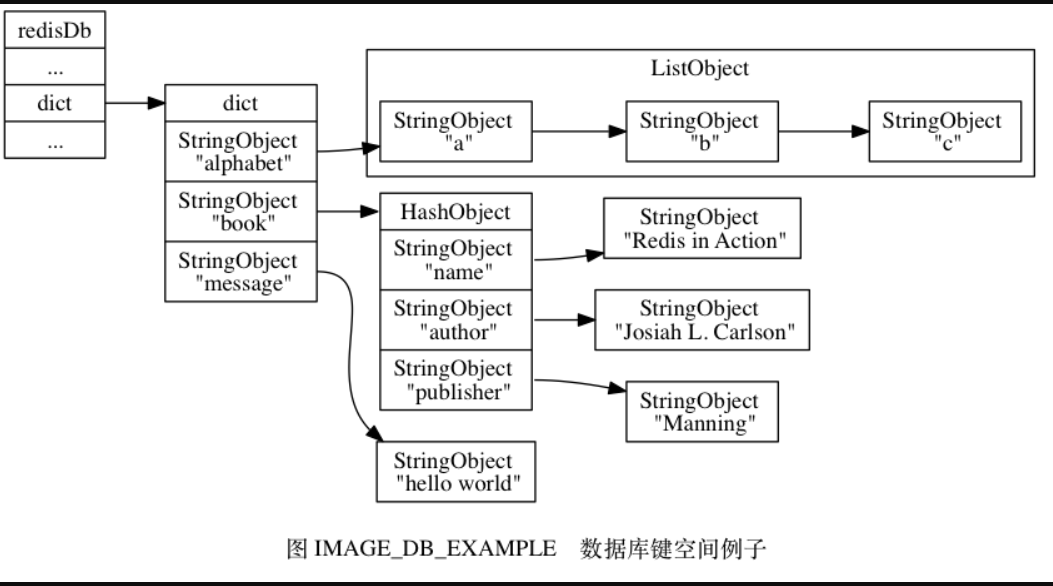
因为数据库的键空间是一个字典, 所以所有针对数据库的操作 —— 比如添加一个键值对到数据库, 或者从数据库中删除一个键值对, 又或者在数据库中获取某个键值对, 等等, 实际上都是通过对键空间字典进行操作来实现的
encoding
通过 encoding 属性来设定对象所使用的编码, 而不是为特定类型的对象关联一种固定的编码, 极大地提升了 Redis 的灵活性和效率, 因为 Redis 可以根据不同的使用场景来为一个对象设置不同的编码, 从而优化对象在某一场景下的效率。
举个例子, 在列表对象包含的元素比较少时, Redis 使用压缩列表作为列表对象的底层实现:
- 因为压缩列表比双端链表更节约内存, 并且在元素数量较少时, 在内存中以连续块方式保存的压缩列表比起双端链表可以更快被载入到缓存中;
- 随着列表对象包含的元素越来越多, 使用压缩列表来保存元素的优势逐渐消失时, 对象就会将底层实现从压缩列表转向功能更强、也更适合保存大量元素的双端链表上面;
其他类型的对象也会通过使用多种不同的编码来进行类似的优化。
redis对象与编码(底层结构)对应关系引入
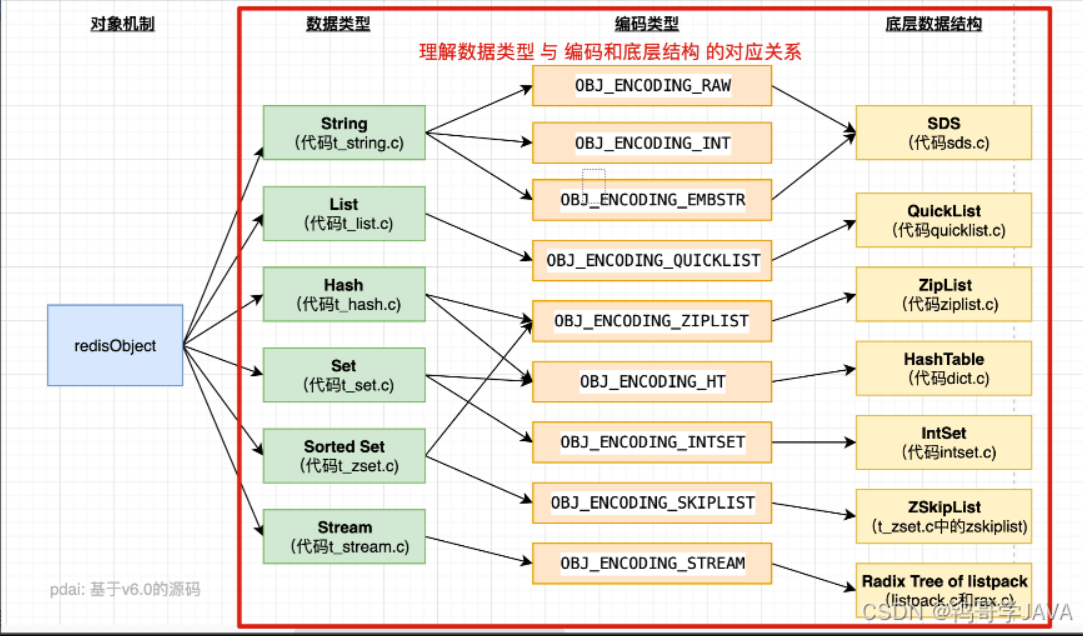
列表对象的编码是quicklist
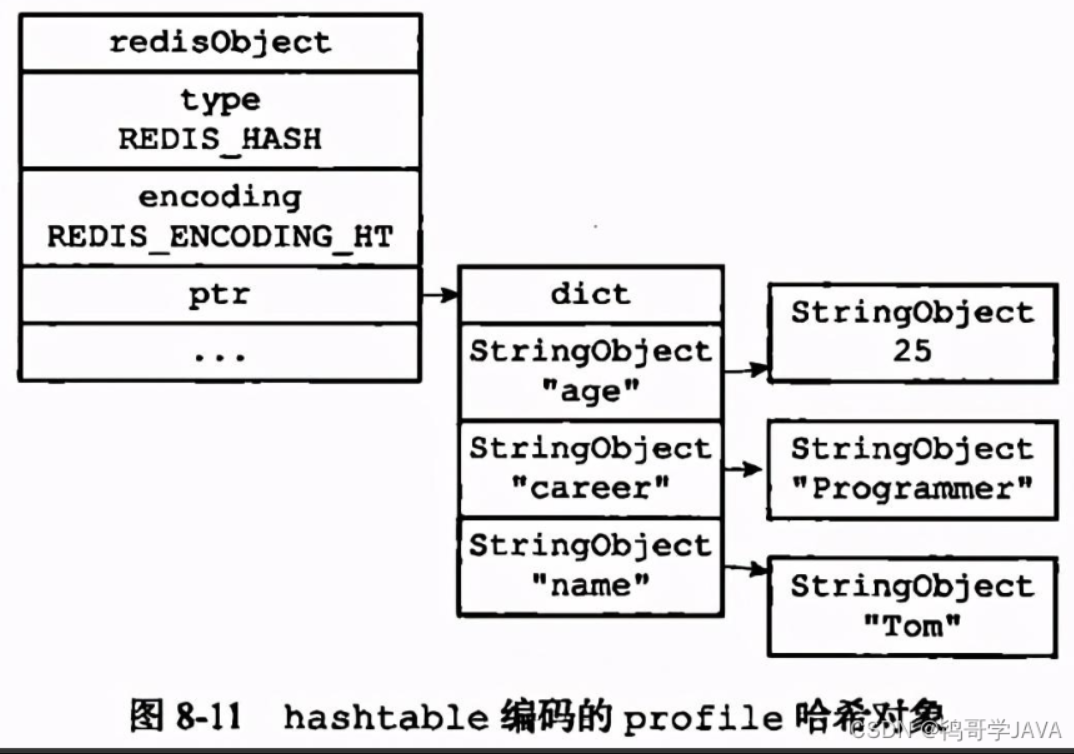
哈希对象,对应的底层实现有两种, 一种是ziplist, 一种是dict。
如果使用ziplist,profile 存储如下:

当使用 hashtable 编码时,上面命令存储如下:
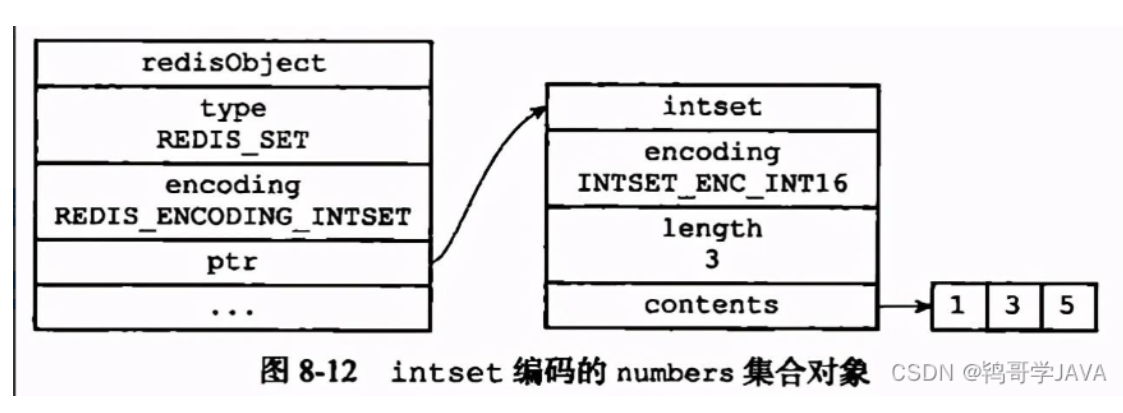
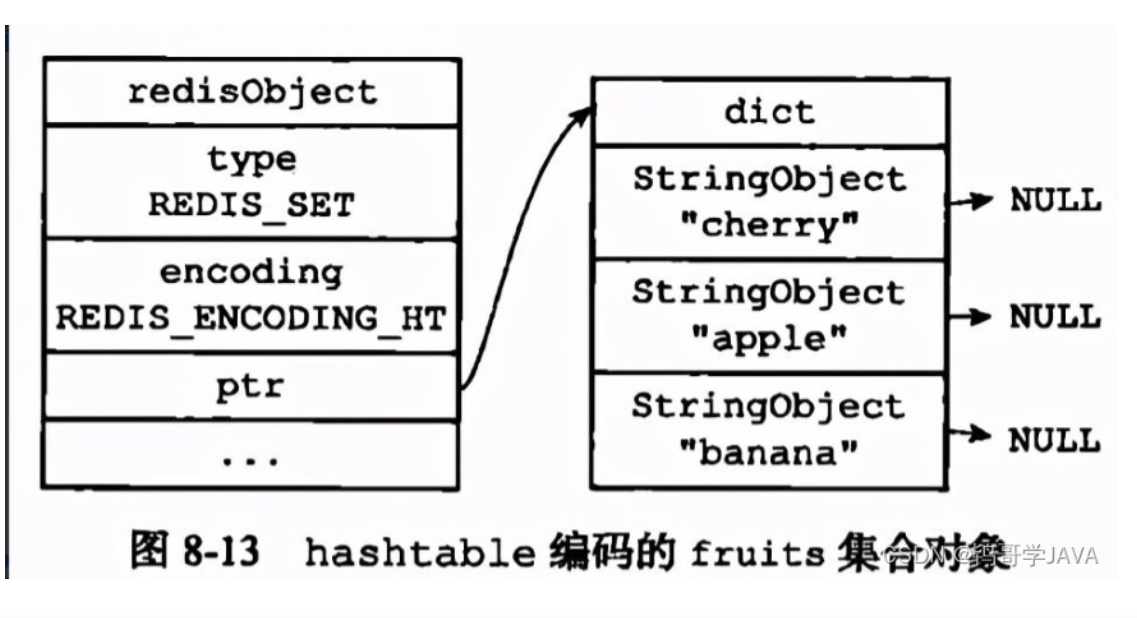
set对象: 底层实现有两种, 分别是intset和hashtable
显然当使用intset作为底层实现的数据结构时, 集合中存储的只能是数值数据, 且必须是整数; 而当使用dict作为集合对象的底层实现时, 是将数据全部存储于dict的键中, 值字段闲置不用.
SADD Dfruits "apple" "cherry" "banana"
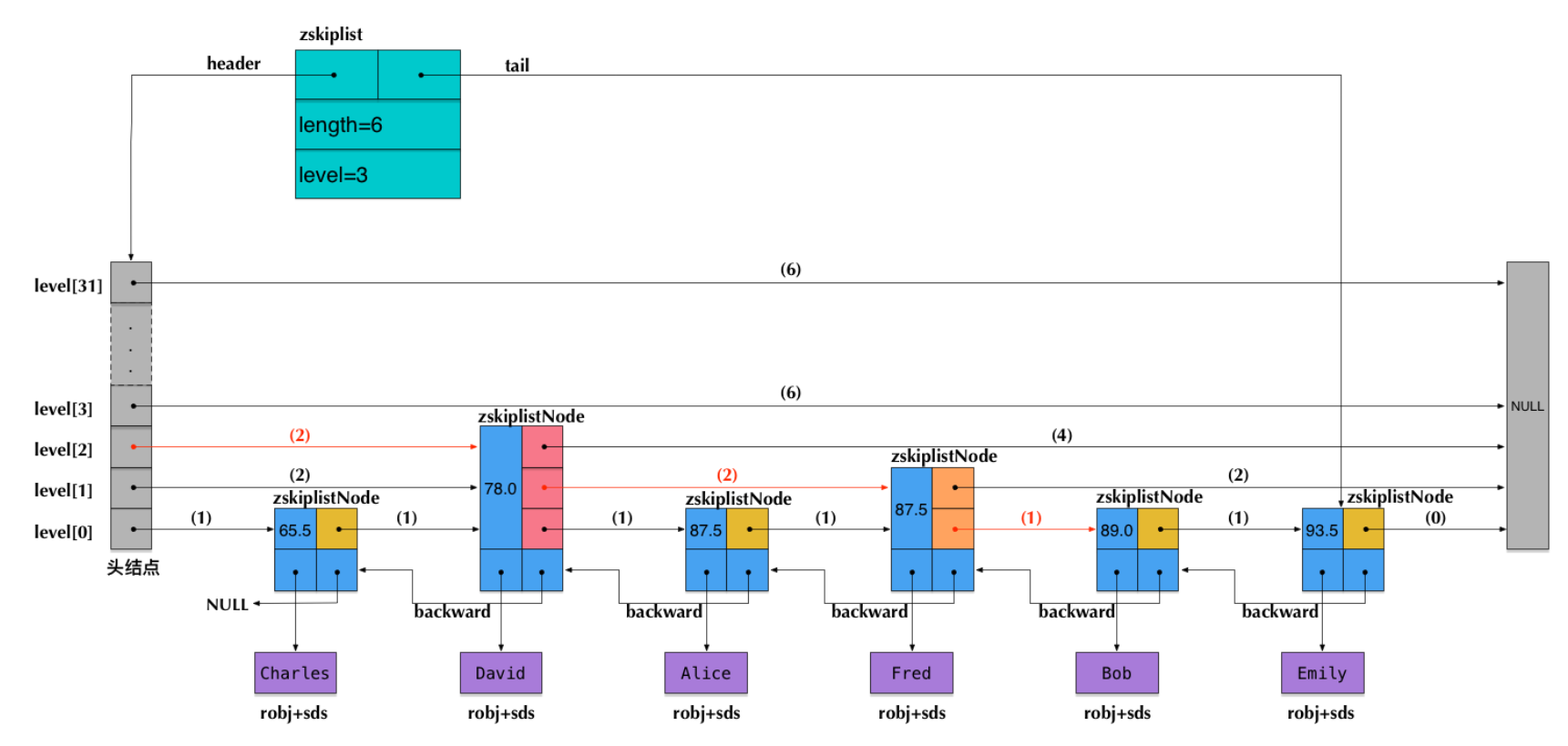
sorted set: 一种是使用ziplist作为底层实现, 另外一种比较特殊, 底层使用了两种数据结构: dict与skiplist
ZADD price 8.5 apple 5.0 banana 6.0 cherry

其实有序集合单独使用字典或跳跃表其中一种数据结构都可以实现,但是这里使用两种数据结构组合起来,原因是假如我们单独使用 字典,虽然能以 O(1) 的时间复杂度查找成员的分值,但是因为字典是以无序的方式来保存集合元素,所以每次进行范围操作的时候都要进行排序;假如我们单独使用跳跃表来实现,虽然能执行范围操作,但是查找操作有 O(1)的复杂度变为了O(logN)。因此Redis使用了两种数据结构来共同实现有序集合。
typedef struct zset{
//跳跃表
zskiplist *zsl;
//字典
dict *dice;
} zset;
dict的key保存元素的值,字典的value保存元素的score,
跳表节点的robj保存元素的成员,节点的score保存对应score。并且会通过指针来共享元素相同的robj和score。
//server.h<br>#define ZSKIPLIST_MAXLEVEL 32
#define ZSKIPLIST_P 0.25
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
zskiplistNode表示skiplist的节点结构
- obj字段存放节点数据,存放string robj。
- score字段对应的是节点的分数。
- backward字段是指向前一个节点的指针,节点只有一个向前指针,最底层是一个双向链表。
- level[]存放各层链表的向后指针结构,包含一个forward ,指向对应层后一个节点;span字段指的是这层的指针跨越了多少个节点值,用于计算排名。(level是一个柔性数组,因此他占用的内存不在zskiplistNode里,也需要单独为其分配内存。)
redis分布式锁
redis事务与乐观锁watch
https://redis.io/docs/manual/transactions/
WATCHed keys are monitored in order to detect changes against them. If at least one watched key is modified before the EXEC command, the whole transaction aborts, and EXEC returns a Null reply to notify that the transaction failed.
WATCH mykey
val = GET mykey
val = val + 1
MULTI
SET mykey $val
EXEC
Using the above code, if there are race conditions and another client modifies the result of val in the time between our call to WATCH and our call to EXEC, the transaction will fail.
So what is WATCH really about? It is a command that will make the EXEC conditional: we are asking Redis to perform the transaction only if none of the WATCHed keys were modified. This includes modifications made by the client, like write commands, and by Redis itself, like expiration or eviction. If keys were modified between when they were WATCHed and when the EXEC was received, the entire transaction will be aborted instead.
the WATCH calls will have the effects to watch for changes starting from the call, up to the moment EXEC is called. You can also send any number of keys to a single WATCH call.
为什么说,watch keys 是一个乐观锁呢?
其实,我们常说的乐观锁,概念是:不管风险,先进行操作,如果没有其他线程争用共享数据,那操作就直接成功了;如果共享的数据的确被争用,产生了冲突,那再进行其他的补偿措施,最常用的补偿措施是不断地重试,直到出现没有竞争的共享数据为止
乐观锁的实现,需要依赖于CAS
CAS指令需要有三个操作数,分别是内存位置(在Java中可以简单地理解为变量的内存地址,用V表示)、旧的预期值(用A表示)和准备设置的新值(用B表示)。
CAS指令执行时,当且仅当V符合A时,处理器才会用B更新V的值,否则它就不执行更新。
但是,不管是否更新了V的值,都会返回V的旧值,上述的处理过程是一个原子操作,执行期间不会被其他线程中断。
CAS的经典就是AtomicInteger,他的incrementAndGet()方法,同时保证了原子性、可见性、有序性这3个特性。
也就是说,只能能提供CAS能力,那么就可以成为乐观锁。
而redis的watch机制,正好提供了CAS能力
首先watch keys(用V表示),此时会记录key的旧值(用A表示),当exec被执行前,认为,所有的命令,都不会出现并发冲突的;但是,当开始执行exec时,会准备给这个key设置新值,在设置新值时,会做一次CAS操作,即当且仅当V符合A时,处理器才会用B更新V的值,否则它就不执行更新
set nx px 悲观锁
/**
* 使用redis的set命令实现获取分布式锁
* @param lockKey 可以就是锁
* @param requestId 请求ID,保证同一性 uuid+threadID
* @param expireTime 过期时间,避免死锁
* @return
*/
public boolean getLock(String lockKey,String requestId,int expireTime) {
//NX:保证互斥性
// hset 原子性操作 只要lockKey有效 则说明有进程在使用分布式锁
String result = jedis.set(lockKey, requestId, "NX", "EX", expireTime);
if("OK".equals(result)) {
return true;
}
return false;
}
释放锁
/**
* 释放分布式锁
* @param lockKey
* @param requestId
*/
public static void releaseLock(String lockKey,String requestId) {
if (requestId.equals(jedis.get(lockKey))) {
jedis.del(lockKey);
}
}
问题在于如果调用jedis.del()方法的时候,这把锁已经不属于当前客户端的时候会解除他人加的锁。那么是否真的有这种场景?答案是肯定的,比如客户端A加锁,一段时间之后客户端A解锁,在执行jedis.del()之前,锁突然过期了,此时客户端B尝试加锁成功,然后客户端A再执行del()方法,则将客户端B的锁给解除了。
redis+lua脚本实现
public static boolean releaseLock(String lockKey, String requestId) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return
redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, Collections.singletonList(lockKey),
Collections.singletonList(requestId));
if (result.equals(1L)) {
return true;
}
return false;
}
延时双删 & cache -aside pattern
Cache-Aside Pattern
具体规则如下:
• 读场景
a.应用尝试从Redis读取缓存数据
b.如miss,应用从数据库中读取数据,并执行步骤3;如hit,则应用直接进行后续业务处理
c.应用将数据写入缓存
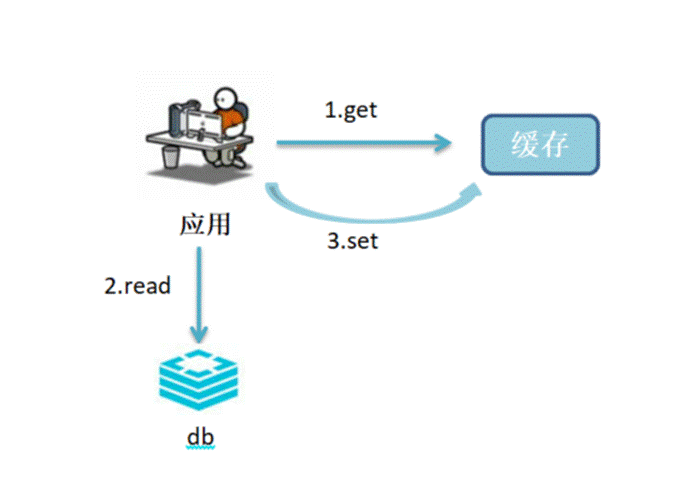
• 写场景
a.应用删除缓存
b.应用将数据写入数据库
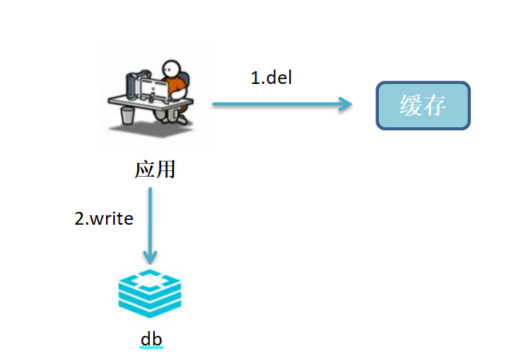
延时双删
上面的cache-aside pattern 的写场景,先删缓存,然后再写数据库。在并发情况下,还是会存在,数据不一致的场景:
2 个线程要并发「读写」数据,可能会发生以下场景:
- 线程 A 要更新 X = 2(原值 X = 1)
- 线程 A 先删除缓存
- 线程 B 读缓存,发现不存在,从数据库中读取到旧值(X = 1)
- 线程 A 将新值写入数据库(X = 2)
- 线程 B 将旧值写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),发生不一致。
为了解决这个问题,这里提供了延时双删的策略:
先删缓存,再更新数据库,过一会儿再删缓存
按照延时双删策略,这 2 个问题的解决方案是这样的:
1.在线程 A 删除缓存、更新完数据库之后,先「休眠一会」,再「删除」一次缓存。
2.线程 A 可以生成一条「延时消息」,写到消息队列中,消费者延时「删除」缓存。
延时队列
延时队列原理:https://zhuanlan.zhihu.com/p/343811173
使用场景:https://www.lovecto.cn/20180829/236.html
使用redisson的延迟队列时,千万要注意的地方是放入队列是使用的RDelayedQueue,获取队列是使用RQueue而不是RDelayedQueue
// 创建一个延时队列,并且添加内容到 延时队列中
private RDelayedQueue<EmployeeTask> delayedQueue;
@PostConstruct
public void init() {
// 初始化redis延时队列
log.info("redisson block queue key -> {}", RedisKeyConst.getEmployeeTaskBlockingQueueKey());
RBlockingDeque<EmployeeTask> blockingDeque = redissonClient.getBlockingDeque(RedisKeyConst.getEmployeeTaskBlockingQueueKey());
delayedQueue = redissonClient.getDelayedQueue(blockingDeque);
}
@Override
public void offerTask(EmployeeTask task, long delay, TimeUnit unit) {
log.info("新增延时任务, info -> {}, delay -> {}, unit -> {}", task, delay, unit);
delayedQueue.offer(task, delay, unit);
}
// 从延时队列中,取出相应的内容
// 初始化redis延时队列
RBlockingDeque<EmployeeTask> blockingDeque = redissonClient.getBlockingDeque(RedisKeyConst.getEmployeeTaskBlockingQueueKey());
// 开启线程轮询队列
CompletableFuture.runAsync(() -> {
while (true) {
try {
EmployeeTask task = blockingDeque.take();
CompletableFuture.runAsync(() -> employeeTaskDelayService.execute(task));
} catch (Throwable e) {
log.error("员工任务延时任务异常", e);
}
}
});
总结下:
被订阅的channel: redisson_delay_queue_channel:{dest_queue1}
sortedSet的key: redisson_delay_queue_timeout:{dest_queue1}
aa redisson_delay_queue:{dest_queue1}
阻塞监听的key: dest_queue1
BLPOP这个阻塞监听的key
先往sortedSet中添加member和score,member为业务数据, score为数据截止时间戳,
将业务数据,添加到aa(这个aa,也不知道,是干啥的)
从sortedSet中,查询最临近要触发的数据,
给被订阅的channel,发送通知 (之前订阅了的客户端,可能是微服务就有多个客户端),内容为将要触发的时间
客户端收到通知后,就在自己进程里面开启延时任务(HashedWheelTimer),到时间后就可以从redis取数据发送
从sortedSet中,查询出业务数据,然后将业务数据,push到阻塞监听的key(dest_queue1),
然后将当前数据从zset移除
我们事先,已经BLPOP这个key,此时会立刻收到业务数据
整合集成
redis & letture & spring 整合
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
配置项如下:
spring:
# redis 配置
redis:
# 地址
host: 221.181.222.135
# 端口,默认为6379
port: 6379
# 数据库索引
database: 0
# 密码
password: long123456
# 连接超时时间
timeout: 15s
lettuce:
pool:
# 连接池中的最小空闲连接
min-idle: 0
# 连接池中的最大空闲连接
max-idle: 8
# 连接池的最大数据库连接数
max-active: 8
# #连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: -1ms
配置类如下:
@Configuration
@EnableCaching
public class RedisConfig extends CachingConfigurerSupport
{
@Bean
@SuppressWarnings(value = { "unchecked", "rawtypes" })
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory)
{
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
FastJson2JsonRedisSerializer serializer = new FastJson2JsonRedisSerializer(Object.class);
// 使用StringRedisSerializer来序列化和反序列化redis的key值
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(serializer);
// Hash的key也采用StringRedisSerializer的序列化方式
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(serializer);
template.afterPropertiesSet();
return template;
}
}
这里配置类,是模仿RedisAutoConfiguration写的,我们看下RedisAutoConfiguration:
// org.springframework.boot.autoconfigure.data.redis.RedisAutoConfiguration
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class)
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
}
我们自定义的配置类,主要是配置key 和 value的序列化类,其中key采用StringRedisSerializer,value采用了FastJson2JsonRedisSerializer。这个FastJson2JsonRedisSerializer,也是我们自定义的,如下:
/**
* Redis使用FastJson序列化
*
* @author yanggq
*/
public class FastJson2JsonRedisSerializer<T> implements RedisSerializer<T>
{
public static final Charset DEFAULT_CHARSET = Charset.forName("UTF-8");
private Class<T> clazz;
public FastJson2JsonRedisSerializer(Class<T> clazz)
{
super();
this.clazz = clazz;
}
@Override
public byte[] serialize(T t) throws SerializationException
{
if (t == null)
{
return new byte[0];
}
return JSON.toJSONString(t, JSONWriter.Feature.WriteClassName).getBytes(DEFAULT_CHARSET);
}
@Override
public T deserialize(byte[] bytes) throws SerializationException
{
if (bytes == null || bytes.length <= 0)
{
return null;
}
String str = new String(bytes, DEFAULT_CHARSET);
return JSON.parseObject(str, clazz, JSONReader.Feature.SupportAutoType);
}
}
与redission整合集成
<dependencies>
<!-- 实现对 Redisson 的自动化配置 -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.11.3</version>
</dependency>
<!-- 方便等会写单元测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 等会示例会使用 fastjson 作为 JSON 序列化的工具 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.61</version>
</dependency>
<!-- Spring Data Redis 默认使用 Jackson 作为 JSON 序列化的工具 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>RELEASE</version>
<scope>test</scope>
</dependency>
</dependencies>
spring:
redis:
database: 0
timeout: 3000
# password:
# 单节点模式
host: 127.0.0.1
port: 6379
# redisson配置文件路径
redisson:
file: classpath:redisson.yml
redisson.yml
# 单节点配置
singleServerConfig:
# 连接空闲超时,单位:毫秒
idleConnectionTimeout: 10000
# 连接超时,单位:毫秒
connectTimeout: 10000
# 命令等待超时,单位:毫秒
timeout: 3000
# 命令失败重试次数,如果尝试达到 retryAttempts(命令失败重试次数) 仍然不能将命令发送至某个指定的节点时,将抛出错误。
# 如果尝试在此限制之内发送成功,则开始启用 timeout(命令等待超时) 计时。
retryAttempts: 3
# 命令重试发送时间间隔,单位:毫秒
retryInterval: 1500
# 密码
password:
# 单个连接最大订阅数量
subscriptionsPerConnection: 5
# 客户端名称
clientName: myredis
# 节点地址
address: redis://127.0.0.1:6379
# 发布和订阅连接的最小空闲连接数
subscriptionConnectionMinimumIdleSize: 1
# 发布和订阅连接池大小
subscriptionConnectionPoolSize: 50
# 最小空闲连接数
connectionMinimumIdleSize: 32
# 连接池大小
connectionPoolSize: 64
# 数据库编号
database: 0
# DNS监测时间间隔,单位:毫秒
dnsMonitoringInterval: 5000
# 线程池数量,默认值: 当前处理核数量 * 2
#threads: 0
# Netty线程池数量,默认值: 当前处理核数量 * 2
#nettyThreads: 0
# 编码
codec: !<org.redisson.codec.JsonJacksonCodec> {}
# 传输模式
transportMode : "NIO"
测试
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
public void testStringSetKey() {
stringRedisTemplate.opsForValue().set("weipeng", "123456789");
}
redisson官方文档
https://github.com/redisson/redisson/wiki
redisson使用范例
https://github.com/redisson/redisson-examples
使用redis分布式锁
@RunWith(SpringRunner.class)
@SpringBootTest
public class LockTest {
private static final String LOCK_KEY = "anylock";
@Autowired // <1>
private RedissonClient redissonClient;
@Test
public void test() throws InterruptedException {
// <2.1> 启动一个线程 A ,去占有锁
new Thread(new Runnable() {
@Override
public void run() {
// 加锁以后 10 秒钟自动解锁
// 无需调用 unlock 方法手动解锁
final RLock lock = redissonClient.getLock(LOCK_KEY);
lock.lock(10, TimeUnit.SECONDS);
}
}).start();
// <2.2> 简单 sleep 1 秒,保证线程 A 成功持有锁
Thread.sleep(1000L);
// <3> 尝试加锁,最多等待 100 秒,上锁以后 10 秒自动解锁
System.out.println(String.format("准备开始获得锁时间:%s", new SimpleDateFormat("yyyy-MM-DD HH:mm:ss").format(new Date())));
final RLock lock = redissonClient.getLock(LOCK_KEY);
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
System.out.println(String.format("实际获得锁时间:%s", new SimpleDateFormat("yyyy-MM-DD HH:mm:ss").format(new Date())));
} else {
System.out.println("加锁失败");
}
}
}
lettuce和redisson可以同时存在吗
lettuce的自动配置类是RedisAutoConfiguration
@Configuration
@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class)
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(
RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
我们看RedisAutoConfiguration,发现向ioc容器中注入了RedisTemplate,这里使用的redisConnectionFactory,类型是LettuceConnectionFactory
接下来,
redisson的自动配置是:RedissonAutoConfiguration
@Configuration
@ConditionalOnClass({Redisson.class, RedisOperations.class})
@AutoConfigureBefore(RedisAutoConfiguration.class) // 表示RedissonAutoConfiguration在RedisAutoConfiguration之前进行应用
@EnableConfigurationProperties({RedissonProperties.class, RedisProperties.class})
public class RedissonAutoConfiguration {
@Autowired
private RedissonProperties redissonProperties;
@Autowired
private RedisProperties redisProperties;
@Autowired
private ApplicationContext ctx;
@Bean
@ConditionalOnMissingBean(name = "redisTemplate") // 这个表示,如果ioc容器,没有redisTemplate,才会新创建一个redisTemplate,注入到ioc容器中
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> template = new RedisTemplate<Object, Object>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean(StringRedisTemplate.class)
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean(RedisConnectionFactory.class)
public RedissonConnectionFactory redissonConnectionFactory(RedissonClient redisson) {
return new RedissonConnectionFactory(redisson);
}
通过上面的2个配置类,我们可以认为:
如果同时配置lettuce和redisson,因为先应用RedissonAutoConfiguration,导致先向ioc注入了RedissonConnectionFactory,并且注入了restTemplate,这个restTemplate使用的是RedissonConnectionFactory;而RedisAutoConfiguration是后应用的,所以这个时候,发现ioc容器中,已经存在了redisTemplate,所以不会再注入使用LettuceConnectionFactory的restTemplate了。
因此,如果同时配置lettuce和redisson,此时使用的restTemplate,其实是redisson提供的,而lettuce提供的restTemplate并没有生效。
如果想同时使用lettuce和redisson,那么就需要自己写一个配置类,来同时创建redisson提供的restTemplate 和 lettuce提供的restTemplate。
redisClient与redisTemplate的关系
// org.redisson.spring.starter.RedissonAutoConfiguration#redisTemplate
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> template = new RedisTemplate<Object, Object>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
// org.redisson.spring.starter.RedissonAutoConfiguration#redissonConnectionFactory
@Bean
@ConditionalOnMissingBean(RedisConnectionFactory.class)
public RedissonConnectionFactory redissonConnectionFactory(RedissonClient redisson) {
return new RedissonConnectionFactory(redisson);
}
看了上面2段代码,就知道了,
首先,需要根据redisClient,才能建造起RedissonConnectionFactory,
然后,根据RedissonConnectionFactory,才能建造起RedisTemplate
也就是说redisClient是最底层,RedissonConnectionFactory是中间层,RedisTemplate是最上层
另一种方式,来整合redissson框架
我们前面,将redisson的配置信息,全部写到了redisson.yml中,其实我们还可以,将配置信息写到java代码中
@Configuration
public class RedissonConfig {
@Resource
private RedisProperties redisProperties;
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.setTransportMode(TransportMode.NIO);
ClusterServersConfig clusterServersConfig = config.useClusterServers();
//可以用"rediss://"来启用SSL连接
clusterServersConfig.addNodeAddress(redisProperties.getCluster().getNodes()
.stream().map(url -> "redis://" + url)
.toArray(String[]::new));
config.setCodec(new JsonJacksonCodec(new ObjectMapper()
.registerModule(new JavaTimeModule())));
return Redisson.create(config);
}
}
为什么,2种方式,都可以呢?
其实,我们只要看一下RedissonAutoConfiguration的代码,就知道了
其实下面的代码,就是获取各种配置信息,然后封装成Config对象,最后根据这个Config对象, 构建一个RedissonClient
首先,@ConditionalOnMissingBean(RedissonClient.class) ,表示,只有我们自己,没有在代码中创建一个RedissonClient,才会执行这里的代码,创建一个RedissonClient
如果我们配置了redisson.yml,其实就是执行这里的redissonProperties.getConfig() != null的分支的代码
// RedissonAutoConfiguration#redisson
@Bean(destroyMethod = "shutdown")
@ConditionalOnMissingBean(RedissonClient.class) // 1
public RedissonClient redisson() throws IOException {
Config config = null;
Method clusterMethod = ReflectionUtils.findMethod(RedisProperties.class, "getCluster");
Method timeoutMethod = ReflectionUtils.findMethod(RedisProperties.class, "getTimeout");
Object timeoutValue = ReflectionUtils.invokeMethod(timeoutMethod, redisProperties);
int timeout;
if(null == timeoutValue){
timeout = 10000;
}else if (!(timeoutValue instanceof Integer)) {
Method millisMethod = ReflectionUtils.findMethod(timeoutValue.getClass(), "toMillis");
timeout = ((Long) ReflectionUtils.invokeMethod(millisMethod, timeoutValue)).intValue();
} else {
timeout = (Integer)timeoutValue;
}
if (redissonProperties.getConfig() != null) {
// 如果我们配置了redisson.yml,就是执行这里的代码
try {
config = Config.fromYAML(redissonProperties.getConfig());
} catch (IOException e) {
try {
config = Config.fromJSON(redissonProperties.getConfig());
} catch (IOException e1) {
throw new IllegalArgumentException("Can't parse config", e1);
}
}
} else if (redissonProperties.getFile() != null) {
try {
InputStream is = getConfigStream();
config = Config.fromYAML(is);
} catch (IOException e) {
// trying next format
try {
InputStream is = getConfigStream();
config = Config.fromJSON(is);
} catch (IOException e1) {
throw new IllegalArgumentException("Can't parse config", e1);
}
}
} else if (redisProperties.getSentinel() != null) {
...
...
} else if (clusterMethod != null && ReflectionUtils.invokeMethod(clusterMethod, redisProperties) != null) {
Object clusterObject = ReflectionUtils.invokeMethod(clusterMethod, redisProperties);
Method nodesMethod = ReflectionUtils.findMethod(clusterObject.getClass(), "getNodes");
List<String> nodesObject = (List) ReflectionUtils.invokeMethod(nodesMethod, clusterObject);
String[] nodes = convert(nodesObject);
config = new Config();
// 看上面我们自定义redissonClient的代码,其实就是模仿这里的,给config设置NodeAddress等属性
config.useClusterServers()
.addNodeAddress(nodes)
.setConnectTimeout(timeout)
.setPassword(redisProperties.getPassword());
} else {
...
...
}
if (redissonAutoConfigurationCustomizers != null) {
for (RedissonAutoConfigurationCustomizer customizer : redissonAutoConfigurationCustomizers) {
customizer.customize(config);
}
}
return Redisson.create(config);
}
连接redis集群
连接1个redis集群
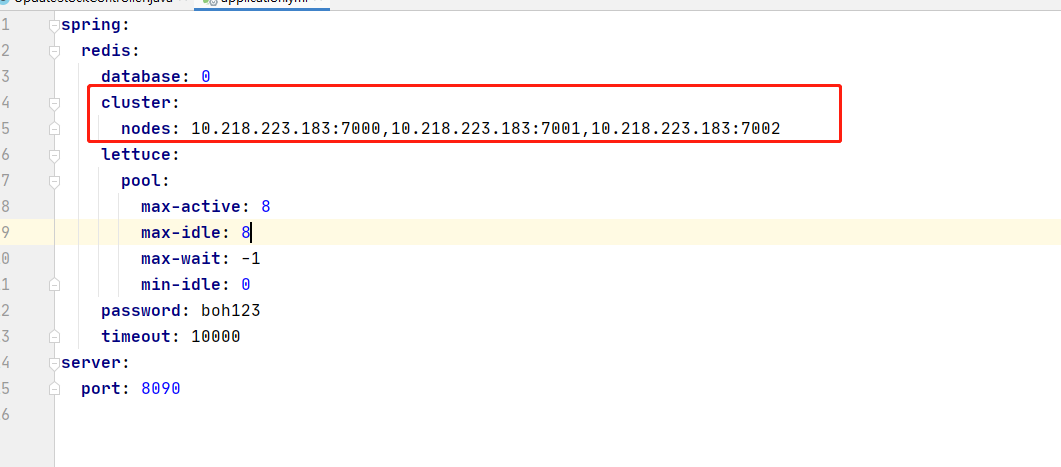
连接多个redis集群
参考:https://www.cnblogs.com/sunch/p/14665804.html
连接一个redis集群,再连接一个redis单机
在看下面代码之前,我们先学习下,spring本身是怎么构建redisTemplate的
spring构建redisTemplate,是借助于2个很重要的类:RedisAutoConfiguration 和 LettuceConnectionConfiguration
LettuceConnectionConfiguration的作用:是一个configuration,将RedisProperties的值,取出来,构建出LettuceClientConfiguration 和 RedisStandaloneConfiguration,然后,再根据LettuceClientConfiguration 与RedisStandaloneConfiguration构建出LettuceConnectionFactory
也就是说,LettuceConnectionConfiguration最终构建出了一个LettuceConnectionFactory
RedisAutoConfiguration 的作用:借助于之前构建出的LettuceConnectionFactory,创建一个redisTemplate对象,注入ioc容器中。
先看一个大概的逻辑图,如下:
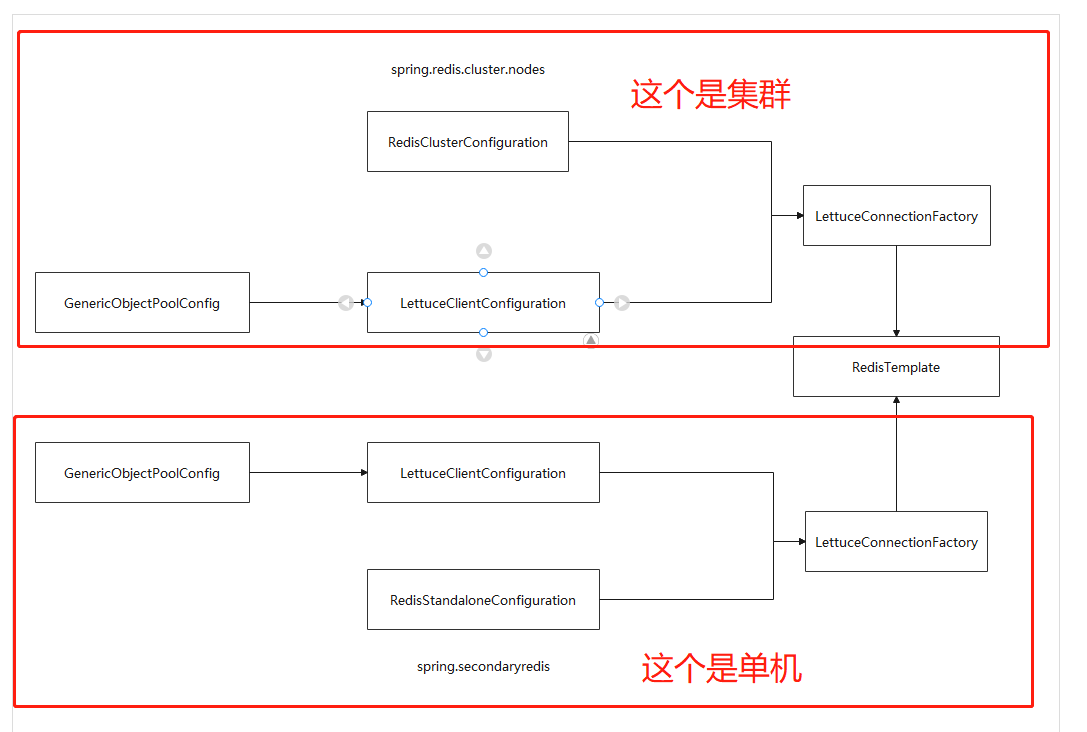
配置文件application.yaml如下:
spring:
fbiredis:
password: boh123 # 密码(默认为空)
timeout: 6000 # 连接超时时长(毫秒)
cluster:
nodes: 10.218.223.183:7000,10.218.223.183:7001,10.218.223.183:7002
max-redirects: 1 # 获取失败 最大重定向次数
lettuce:
pool:
max-active: 1000 # 连接池最大连接数(使用负值表示没有限制)
max-wait: -1ms # 连接池最大阻塞等待时间(使用负值表示没有限制)
max-idle: 10 # 连接池中的最大空闲连接
min-idle: 5 # 连接池中的最小空闲连接
apiredis:
database: 0
host-name: 10.218.221.78
port: 7000
lettuce:
pool:
max-active: 8
max-idle: 8
max-wait: -1
min-idle: 0
password:
timeout: 10000
WpRedisConfigConfiguration:
package com.wp.redisserveralwp.config;
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.env.Environment;
import org.springframework.core.env.MapPropertySource;
import org.springframework.data.redis.connection.RedisClusterConfiguration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.connection.RedisStandaloneConfiguration;
import org.springframework.data.redis.connection.lettuce.LettuceClientConfiguration;
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory;
import org.springframework.data.redis.connection.lettuce.LettucePoolingClientConfiguration;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
/**
* 类描述:
*
* @Author weipeng
* @Date 2021/7/7
* @Version 1.0
*/
@Configuration
public class WpRedisConfigConfiguration {
@Autowired
private Environment environment;
/**
* 配置lettuce连接池
*/
@Bean("fbiRedisPool")
@Primary
@ConfigurationProperties (prefix = "spring.fbiredis.cluster.lettuce.pool")
public GenericObjectPoolConfig fbiRedisPool() {
return new GenericObjectPoolConfig();
}
/**
* 配置第一个数据源的
*/
@Bean ("fbiRedisClusterConfig")
@Primary
public RedisClusterConfiguration fbiRedisClusterConfig() {
Map<String, Object> source = new HashMap<>(8);
source.put("spring.redis.cluster.nodes", environment.getProperty("spring.fbiredis.cluster.nodes"));
RedisClusterConfiguration redisClusterConfiguration;
redisClusterConfiguration = new RedisClusterConfiguration(new MapPropertySource("RedisClusterConfiguration",
source));
redisClusterConfiguration.setPassword(environment.getProperty("spring.fbiredis.password"));
return redisClusterConfiguration;
}
/**
* 配置第一个数据源的连接工厂
* 这里注意:需要添加@Primary 指定bean的名称,目的是为了创建两个不同名称的LettuceConnectionFactory
*/
@Bean ("fbiLettuceConnectionFactory")
@Primary
public LettuceConnectionFactory fbiLettuceConnectionFactory(@Qualifier("fbiRedisPool") GenericObjectPoolConfig redisPool, @Qualifier (
"fbiRedisClusterConfig") RedisClusterConfiguration redisClusterConfig) {
LettuceClientConfiguration clientConfiguration =
LettucePoolingClientConfiguration.builder().poolConfig(redisPool).build();
return new LettuceConnectionFactory(redisClusterConfig, clientConfiguration);
}
/**
* 配置第一个数据源的RedisTemplate
* 注意:这里指定使用名称=factory 的 RedisConnectionFactory
* 并且标识第一个数据源是默认数据源 @Primary
*/
@Bean ("fbiRedisTemplate")
@Primary
public RedisTemplate fbiRedisTemplate(@Qualifier ("fbiLettuceConnectionFactory") RedisConnectionFactory redisConnectionFactory) {
return getRedisTemplate(redisConnectionFactory);
}
/*** 功能描述: 根据连接工厂获取一个RedisTemplate
*/
private StringRedisTemplate getRedisTemplate(RedisConnectionFactory factory) {
StringRedisTemplate stringRedisTemplate = new StringRedisTemplate();
stringRedisTemplate.setConnectionFactory(factory);
return stringRedisTemplate;
}
/**
* ----------------------------------------------------------------------------
*
* 以下属于,配置单机redis的代码
*
*
* ------------------------------------------------------------------------------
*/
/**
* 配置lettuce连接池
*/
@Bean("apiRedisPool")
@ConfigurationProperties (prefix = "spring.apiredis.lettuce.pool")
public GenericObjectPoolConfig apiRedisPool() {
return new GenericObjectPoolConfig();
}
@Bean(name="apiRedisConfig")
@ConfigurationProperties(prefix="spring.apiredis")
public RedisStandaloneConfiguration apiRedisConfig() {
return new RedisStandaloneConfiguration();
}
@Bean("apiLettuceFactory")
public LettuceConnectionFactory apiLettuceFactory(@Qualifier("apiRedisPool") GenericObjectPoolConfig poolConfig,
@Qualifier ("apiRedisConfig") RedisStandaloneConfiguration redisStandaloneConfiguration) {
LettuceClientConfiguration clientConfiguration = LettucePoolingClientConfiguration.builder().poolConfig(poolConfig).build();
return new LettuceConnectionFactory(redisStandaloneConfiguration,clientConfiguration);
}
/**
* 配置第一个数据源的RedisTemplate
* 注意:这里指定使用名称=factory 的 RedisConnectionFactory
* 并且标识第一个数据源是默认数据源 @Primary
*/
@Bean ("apiRedisTemplate")
@Primary
public RedisTemplate apiRedisTemplate(@Qualifier ("apiLettuceFactory") RedisConnectionFactory redisConnectionFactory) {
return getRedisTemplate(redisConnectionFactory);
}
}
测试代码如下:
package com.wp.redisserveralwp;
import javax.annotation.Resource;
import java.util.Map;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.context.ApplicationContext;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
@SpringBootTest
class RedisServeralWpApplicationTests {
@Resource(name = "fbiRedisTemplate")
private RedisTemplate fbiRedisTemplate;
@Resource(name = "apiRedisTemplate")
private RedisTemplate apiRedisTemplate;
@Autowired
private ApplicationContext applicationContext;
@Test
void contextLoads() {
apiRedisTemplate.opsForValue().set("wppppp","11111");
fbiRedisTemplate.opsForValue().set("weipeng","666666666");
Map<String, RedisConnectionFactory> redisConnectionFactoryMap = applicationContext.getBeansOfType(RedisConnectionFactory.class);
Map<String, RedisTemplate> redisTemplateMap = applicationContext.getBeansOfType(RedisTemplate.class);
}
}
SessionCallback & RedisCallback
redisTemplate提供了SessionCallback 和 RedisCallback这2种callback
// org.springframework.data.redis.core.RedisTemplate#execute(org.springframework.data.redis.core.RedisCallback<T>)
public <T> T execute(RedisCallback<T> action) {
return execute(action, isExposeConnection());
}
// org.springframework.data.redis.core.RedisTemplate#executePipelined(org.springframework.data.redis.core.SessionCallback<?>)
public List<Object> executePipelined(SessionCallback<?> session) {
return executePipelined(session, valueSerializer);
}
接下来,我们看下RedisCallback 和 SessionCallback的定义:
/**
* Callback interface for Redis 'low level' code. To be used with {@link RedisTemplate} execution methods, often as
* anonymous classes within a method implementation. Usually, used for chaining several operations together (
* {@code get/set/trim etc...}.
*
* @author Costin Leau
*/
public interface RedisCallback<T> {
/**
* Gets called by {@link RedisTemplate} with an active Redis connection. Does not need to care about activating or
* closing the connection or handling exceptions.
*
* @param connection active Redis connection
* @return a result object or {@code null} if none
* @throws DataAccessException
*/
@Nullable
T doInRedis(RedisConnection connection) throws DataAccessException;
}
/**
* Callback executing all operations against a surrogate 'session' (basically against the same underlying Redis
* connection). Allows 'transactions' to take place through the use of multi/discard/exec/watch/unwatch commands.
*
* @author Costin Leau
*/
public interface SessionCallback<T> {
/**
* Executes all the given operations inside the same session.
*
* @param operations Redis operations
* @return return value
*/
@Nullable
<K, V> T execute(RedisOperations<K, V> operations) throws DataAccessException;
}
可以看到,提供RedisCallback的目的是:
-
将一些底层的能力,暴露出来。我们常用的restTemplate,只提供了一些常用的redis命令的封装,但是对一些不常用的、复杂的redis命令,并没有提供上层封装。如果,开发者需要使用这些未封装的命令,就可以利用RedisCallback中提供的RedisConnection,来实现
-
如果某个业务操作,需要由多个链式操作命令,聚合实现,比如get/set/trim等,此时就可以考虑使用RedisCallback中提供的RedisConnection,来实现
可以看到,提供SessionCallback的目的是:
- 在执行事务相关的命令时,比如multi/discard/exec/watch/unwatch commands,需要使用SessionCallback。
其实,我们的restTemplate封装的命令,也是使用RedisCallback 和 SessionCallback实现的。我们看下redisTemplate.opsForValue().get(key) 这个命令,源码是怎么实现的:
public ValueOperations<K, V> opsForValue() {
return valueOps;
}
opsForValue方法,返回的是ValueOperations对象。执行ValueOperations对象的get方法,如下:
// org.springframework.data.redis.core.DefaultValueOperations#get(java.lang.Object)
public V get(Object key) {
return execute(new ValueDeserializingRedisCallback(key) {
@Override
protected byte[] inRedis(byte[] rawKey, RedisConnection connection) {
return connection.get(rawKey);
}
}, true);
}
可以看到,其实这里使用了ValueDeserializingRedisCallback这个类。而这个ValueDeserializingRedisCallback其实就是,我们上面说的RedisCallback的实现类,如下:
abstract class ValueDeserializingRedisCallback implements RedisCallback<V> {
private Object key;
public ValueDeserializingRedisCallback(Object key) {
this.key = key;
}
public final V doInRedis(RedisConnection connection) {
byte[] result = inRedis(rawKey(key), connection);
return deserializeValue(result);
}
@Nullable
protected abstract byte[] inRedis(byte[] rawKey, RedisConnection connection);
}
我们可以看到,doInRedis方法中,首先调用rawKey方法,将key有字符串,序列化成byte数组;然后去redis中执行命令,得到result,这result也是byte数组;最后,将result由byte数组,反序列化成一个对象。
其中,第2步,也是利用了RedisCallback中的RedisConnection对象,去执行redis命令,才拿到key对应的value值的。
区别
上面,我们知道了RedisCallback 和 SessionCallback的作用了,下面,我们思考下,他们2个,有什么区别?
其实,区别,就在于使用事务的场景。
简单介绍下redis的几个事务命令:
redis事务四大指令: MULTI、EXEC、DISCARD、WATCH。
这四个指令构成了redis事务处理的基础。
1.MULTI用来组装一个事务;
2.EXEC用来执行一个事务;
3.DISCARD用来取消一个事务;
4.WATCH类似于乐观锁机制里的版本号。
被WATCH的key如果在事务执行过程中被并发修改,则事务失败。需要重试或取消。
spring-data-redis 的官方手册。
这里,我们注意这么一句话:
Redis provides support for transactions through the multi, exec, and discard commands. These operations are available on RedisTemplate. However, RedisTemplate is not guaranteed to execute all operations in the transaction with the same connection.
意思是redis服务器通过multi,exec,discard提供事务支持。这些操作在RedisTemplate中已经实现。然而,RedisTemplate不保证在同一个连接中执行所有的这些一个事务中的操作。
另外一句话:
Spring Data Redis provides the SessionCallback interface for use when multiple operations need to be performed with the same connection, such as when using Redis transactions. The following example uses the multi method:
意思是:spring-data-redis也提供另外一种方式,这种方式可以保证多个操作(比如使用redis事务)可以在同一个连接中进行。示例如下:
//execute a transaction
List<Object> txResults = redisTemplate.execute(new SessionCallback<List<Object>>() {
public List<Object> execute(RedisOperations operations) throws DataAccessException {
operations.multi();
operations.opsForSet().add("key", "value1");
// This will contain the results of all operations in the transaction
return operations.exec();
}
});
System.out.println("Number of items added to set: " + txResults.get(0));
也就是说,使用RedisCallback 和 SessionCallback,都能执行多个redis命令,但是SessionCallback能保证,这多个redis命令,使用的是同一个连接中进行的;而RedisCallback,是不能保证这多个redis命令,使用的是同一个连接。
接下来,我们再思考,不使用同一个连接,会有什么问题?
我们先执行
set bb "wp"
我们看一个代码,如下:
Object result = redisTemplate.execute(new RedisCallback<String>() {
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
connection.multi();
connection.set("aa".getBytes(StandardCharsets.UTF_8), "zhangsan".getBytes(StandardCharsets.UTF_8));
// 在执行这个命令之前,先执行set bb "wp",模拟 对一个非整形数据进行原子 +1操作,因为bb对应的值,是一个字符串,所以这里执行自增命令,肯定会失败
connection.incr("bb".getBytes(StandardCharsets.UTF_8));
connection.exec();
return "";
}
});
如果不使用同一个连接,先执行set aa zhangsan命令,再执行incr bb命令,很有可能会出现aa设置成功了,但是incr bb执行失败了。导致的结果是,我们再执行get aa,是能查到值,值为zhangsan。
实际输出
> get aa
"zhangsan
这个其实不是我们想要的,我们既然将2个操作,放到一个事务中,肯定是希望,这2个操作,要么都成功;要么都失败。肯定是不能接收,一个命令成功了,另一个命令失败了。
那如果,我们使用同一个连接的SessionCallback,能解决上面的这个问题吗?如下:
set bb "wp"
Object result = redisTemplate.execute(new SessionCallback() {
@Override
public Object execute(RedisOperations operations) throws DataAccessException {
operations.multi();
operations.opsForValue().set("aa","zhangsan");
// 在执行这个命令之前,先执行set bb "wp",模拟 对一个非整形数据进行原子 +1操作,因为bb对应的值,是一个字符串,所以这里执行自增命令,肯定会失败
operations.opsForValue().increment("bb");
operations.exec();
return null;
}
});
执行后,我们执行以下命令:
> get aa
(nil)
可以看到,aa也没有设置成功,这就证明了set aa命令 和 incr bb命令,都失败了。这个结果,是我们想要的。
综上,如果要想保证事务中,多个操作同时成功 或者同时失败,那么必须使用同一个连接,也即必须使用SessionCallback。