upload-download
yum -y install lrzsz
# 上传
rz
# 下载
sz 服务器的file路径
sz命令是利用ZModem协议来从Linux服务器传送文件到本地
常用参数
-a: 以文本方式传输(ascii)。
-b: 以二进制方式传输(binary)。
-e: 对控制字符转义(escape),这可以保证文件传输正确。
sz -8be myfile.tiff
vim
1.安装软件包
yum -y install vim*
2.配置
vim /etc/vimrc
添加一下命令
set nu " 设置显示行号
set showmode " 设置在命令行界面最下面显示当前模式等
set autoindent " 设置每次单击Enter键后,光标移动到下一行时与上一行的起始字符对齐
syntax on " 即设置语法检测,当编辑C或者Shell脚本时,关键字会用特殊颜色显示
删除/复制
删除单行内容:
将光标移动到需要删除的行
按一下ESC键,确保退出编辑模式
按两次键盘上面的d键,就可以删除了。
删除所有的行:
按一下ESC键,确保退出编辑模式
按一下:冒号键,shift + ; 就可以输入:冒号了。
然后输入%d。%表示文件中的所有行。
删除多行:
将光标移动到需要删除的行
按一下ESC键,确保退出编辑模式
在dd命令前面加上要删除的行数。例如,如果要删除第4行以下的3行,请按下 3 dd
全选(高亮显示):按esc后,然后ggvG或者ggVG
**全部复制:**按esc后,然后ggyG
**全部删除:**按esc后,然后dG
解析:
gg:是让光标移到首行,在vim才有效,vi中无效
v : 是进入Visual(可视)模式
**G :**光标移到最后一行
选中内容以后就可以其他的操作了,比如:
d 删除选中内容
y 复制选中内容到0号寄存器
"+y 复制选中内容到+寄存器,也就是系统的剪贴板,供其他程序用
查找文件find
Linux find 命令用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则 find 命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
语法
find path -option [ -print ] [ -exec -ok command ] {} \;
常用示例
find / -name mobileordering-base.api.jar
参数说明 :
find 根据下列规则判断 path 和 expression,在命令列上第一个 - ( ) , ! 之前的部份为 path,之后的是 expression。如果 path 是空字串则使用目前路径,如果 expression 是空字串则使用 -print 为预设 expression。
expression 中可使用的选项有二三十个之多,在此只介绍最常用的部份。
-mount, -xdev : 只检查和指定目录在同一个文件系统下的文件,避免列出其它文件系统中的文件
-amin n : 在过去 n 分钟内被读取过
-anewer file : 比文件 file 更晚被读取过的文件
-atime n : 在过去n天内被读取过的文件
-cmin n : 在过去 n 分钟内被修改过
-cnewer file :比文件 file 更新的文件
-ctime n : 在过去n天内被修改过的文件
-empty : 空的文件-gid n or -group name : gid 是 n 或是 group 名称是 name
-ipath p, -path p : 路径名称符合 p 的文件,ipath 会忽略大小写
-name name, -iname name : 文件名称符合 name 的文件。iname 会忽略大小写
-size n : 文件大小 是 n 单位,b 代表 512 位元组的区块,c 表示字元数,k 表示 kilo bytes,w 是二个位元组。
-type c : 文件类型是 c 的文件。
d: 目录
c: 字型装置文件
b: 区块装置文件
p: 具名贮列
f: 一般文件
l: 符号连结
s: socket
-pid n : process id 是 n 的文件
你可以使用 ( ) 将运算式分隔,并使用下列运算。
exp1 -and exp2
! expr
-not expr
exp1 -or exp2
exp1, exp2
实例
将当前目录及其子目录下所有文件后缀为 .c 的文件列出来:
# find . -name "*.c"
将当前目录及其子目录中的所有文件列出:
# find . -type f
将当前目录及其子目录下所有最近 20 天内更新过的文件列出:
# find . -ctime -20
find . -name ".erlang.cookie"
nohup---后台启动
nohup 英文全称 no hang up(不挂起),用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行。
nohup 命令,在默认情况下(非重定向时),会输出一个名叫 nohup.out 的文件到当前目录下,如果当前目录的 nohup.out 文件不可写,输出重定向到 $HOME/nohup.out 文件中。
格式:
nohup Command [ Arg … ] [ & ]
Command:要执行的命令。
Arg:一些参数,可以指定输出文件。
&:让命令在后台执行,终端退出后命令仍旧执行。
nslookup
nslookup命令用于**查询DNS的记录,查看域名解析是否正常
nslookup baidu.com
ln 命令
它的功能是为某一个文件在另外一个位置建立一个同步的链接。
当我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要的目录下都放一个必须相同的文件,我们只要在某个固定的目录,放上该文件,然后在 其它的目录下用ln命令链接(link)它就可以,不必重复的占用磁盘空间。
ln [参数][源文件或目录][目标文件或目录]
软链接:
- 1.软链接,以路径的形式存在。类似于Windows操作系统中的快捷方式
- 2.软链接可以 跨文件系统 ,硬链接不可以
- 3.软链接可以对一个不存在的文件名进行链接
- 4.软链接可以对目录进行链接
必要参数:
- -b 删除,覆盖以前建立的链接
- -d 允许超级用户制作目录的硬链接
- -f 强制执行
- -i 交互模式,文件存在则提示用户是否覆盖
- -n 把符号链接视为一般目录
- -s 软链接(符号链接)
- -v 显示详细的处理过程
给文件创建软链接,为log2013.log文件创建软链接link2013,如果log2013.log丢失,link2013将失效:
ln -s log2013.log link2013
[root@localhost test]# ll
-rw-r--r-- 1 root bin 61 11-13 06:03 log2013.log
[root@localhost test]# ln -s log2013.log link2013
[root@localhost test]# ll
lrwxrwxrwx 1 root root 11 12-07 16:01 link2013 -> log2013.log
-rw-r--r-- 1 root bin 61 11-13 06:03 log2013.log
Tar---压缩与解压
tar有2个作用,打包和压缩
打包:是指把文件整合在一起,不压缩
压缩:把打包好的文件压缩,便于存储
打包参数如下:
- c: 创建文档
- t: 列出存档内容
- x:提取存档
- f: filename 要操作的文档名
- v:详细信息
压缩参数如下:
- z 用于gzip压缩: filename.tar.gz
- j 用于bzip压缩: filename.tar.bz2
- J 用于xz压缩: filename.tar.xz
打包和提取命令如下:
1.将文件打包:tar cf a.tar /etc/
3.提取文档内容:tar xf a.tar
压缩和解压缩命令如下:
gzip压缩:tar zcf a.tar.gz a.tar
解压: tar zxf a.tar.gz
工作中使用
# 压缩
tar zcf agentwp.tar.gz agent/
# 解压缩
tar zxf agentwp.tar.gz
Grep
The grep filter searches a file for a particular pattern of characters, and displays all lines that contain that pattern. The pattern that is searched in the file is referred to as the regular expression (grep stands for global search for regular expression and print out).
Syntax:
grep [options] pattern [files]
Options Description
-c : This prints only a count of the lines that match a pattern
-h : Display the matched lines, but do not display the filenames.
-i : Ignores, case for matching
-l : Displays list of a filenames only.
-n : Display the matched lines and their line numbers.
-v : This prints out all the lines that do not matches the pattern
-e exp : Specifies expression with this option. Can use multiple times.
-f file : Takes patterns from file, one per line.
-E : Treats pattern as an extended regular expression (ERE)
-w : Match whole word
-o : Print only the matched parts of a matching line,
with each such part on a separate output line.
-A n : Prints searched line and nlines after the result.
-B n : Prints searched line and n line before the result.
-C n : Prints searched line and n lines after before the result.
-E option
‘grep’ ‘-E’ 选项表示使用扩展的正则表达式。如果你使用 ‘grep’ 命令时带 ‘-E’,你只需要用途 ‘|’ 来分隔OR条件。
下面,这个命令的含义是:在filename文本文件中,找到pattern1 或者 pattern2
grep -E 'pattern1|pattern2' filename
-v option
这里主要介绍-v参数
-v, --invert-match: Invert the sense of matching, to select non-matching lines. # 反过来,只打印没有匹配的,而匹配的反而不打印
啥意思呢?
简单来说,正常情况下,是输出匹配的数据,但是加上-v,就输出不匹配的数据。
样例如下:
[root@hecs-358035 wp_awk]# cat test.txt
this is heifei
this is nanjing
this is suzhou
# 输出,不含有suzhou字符的数据
[root@hecs-358035 wp_awk]# cat test.txt | grep -v suzhou
this is heifei
this is nanjing
再看一个样例
# 正常情况下,使用grep ,输出的数据中,除了匹配到的数据,还有一个grep本身的进程
[root@hecs-358035 wp_awk]# ps aux | grep mysql
root 15644 0.0 0.0 112812 976 pts/0 R+ 16:33 0:00 grep --color=auto mysql
mysql 24995 0.0 11.2 1147448 211640 ? Sl 09:35 0:11 /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid
# 这里,只输出匹配到数据,排除grep本身的进程
[root@hecs-358035 wp_awk]# ps aux | grep mysql | grep -v grep
mysql 24995 0.0 11.2 1147448 211640 ? Sl 09:35 0:11 /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid
Awk
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。
之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
awk [选项参数] 'script' var=value file(s)
这里主要说的是awk,指的是,取出第几列的数据
新建一个文件,内容如下:
this is heifei
this is nanjing
this is suzhou
接下来,使用awk,来获取第1列 和 第3列,并输出
# 每行按空格或TAB分割,输出第1列 和 第3列
awk '{print $1,$3}' test.txt
this heifei
this nanjing
this suzhou
接下来,配合head 和 wc使用
# head -1,表示只取第一行的数据
[root@hecs-358035 wp_awk]# awk '{print $1,$3}' test.txt | head -1
this heifei
# wc -l,表示统计有几行
[root@hecs-358035 wp_awk]# awk '{print $1,$3}' test.txt | wc -l
3
下面看一个复杂的综合例子:
[root@hecs-358035 wp_awk]# ps aux | grep mysql
root 15270 0.0 0.0 112812 976 pts/0 R+ 16:27 0:00 grep --color=auto mysql
mysql 24995 0.0 11.2 1147448 211640 ? Sl 09:35 0:11 /usr/sbin/mysqld --daemonize --pid-file=/var/run/mysqld/mysqld.pid
# 将mysql的进程号,保存到wpPid.txt 中
[root@hecs-358035 wp_awk]# ps aux | grep mysql | grep -v grep | awk '{print $2}' | xargs echo >> wpPid.txt
[root@hecs-358035 wp_awk]# cat wpPid.txt
24995
Xargs
本文要为大家介绍的命令是 xargs,我们把它称为护花使者,因为它总是乐于协助其他的命令来完成一些事情。下面一起来看看它是如何护花的。
xargs 是 execute arguments 的缩写,它的作用是从标准输入中读取内容,并将此内容传递给它要协助的命令,并作为那个命令的参数来执行。
坊间有一种说法,将 xargs 解读为乘号(x)和参数(args)的合体,很形象地表达了 xargs 的作用所在。
xargs 和管道不得不说的故事
为了能够为大家解释清楚 xargs 和管道的关系,我们这次选用了更加典型的 cat 命令来为大家举例。
为什么选择 cat 命令呢?众所周知,cat 命令可以接收文件名作为参数,执行后会显示出文件的内容。但是 cat 命令不能直接从标准输入接收参数,正如下面的例子:
#cat后面直接指定china.txt参数, 可以展示china.txt文件的内容
[roc@roclinux ~]$ cat china.txt
hello beijing
#我们尝试通过标准输入把参数传给cat, 结果却只是显示了文件名而已
[roc@roclinux ~]$ echo china.txt | cat
china.txt
从上面的例子中,我们可以得出下面的结论:
- 管道可以实现:将前面的标准输出作为后面的“标准输入”。
- 管道无法实现:将前面的标准输出作为后面的“命令参数”。
这个时候,就要有请 xargs 这位护花使者了。xargs 所擅长的正是“将标准输入作为其指定命令的参数”。说着有些拗口,但我相信大家懂的。
#xargs果然不负众望, 协助cat完成了使命
[roc@roclinux ~]$ echo china.txt | xargs cat
hello beijing
工作中的实际使用
ps aux |grep "mobileordering-base.api.jar" |grep phhs|grep 8083 |grep -v grep |awk '{print $2}'|xargs kill -9
Sed
Linux/UNIX中的sed命令是Stream Editor文本流编辑的缩写,它能同时处理多个文件多行的内容,比如文搜索,查找和替换,插入或删除。虽然sed命令在Linux/UNIX中最常见的用途是替代或查找。通过使用sed,您甚至可以在不打开文件的情况下编辑文件,这比先在VI编辑器中打开文件然后更改文件要快得多。
- sed是一个强大的文本流编辑器。可以做插入、删除、搜索和替换(替换)。
- Linux/UNIX中的sed命令支持正则表达式,从而可以执行复杂的模式匹配。
语法:
set [option] 'command' input_file
其中option是可选的,常用的option有以下几种:
- -n 使用安静(silent)模式(为什么不是-s呢?)。在一般sed的用法中,所有来自stdin的内容一般都会被列出到屏幕上。但如果加上-n参数后,则只有经过sed特殊处理的那一行(或者动作)才会被列出来;
- -e 直接在指令列模式上进行 sed 的动作编辑;
- -f 直接将 sed 的动作写在一个文件内, -f filename 则可以执行filename内的sed命令;
- -r 让sed命令支持扩展的正则表达式(默认是基础正则表达式);
- -i 直接修改读取的文件内容,而不是由屏幕输出。
常用的命令有以下几种:
- a \: append即追加字符串, a \的后面跟上字符串s(多行字符串可以用\n分隔),则会在当前选择的行的后面都加上字符串s;
- c \: 取代/替换字符串,c \后面跟上字符串s(多行字符串可以用\n分隔),则会将当前选中的行替换成字符串s;
- d: delete即删除,该命令会将当前选中的行删除;
- i \: insert即插入字符串,i \后面跟上字符串s(多行字符串可以用\n分隔),则会在当前选中的行的前面都插入字符串s;
- p: print即打印,该命令会打印当前选择的行到屏幕上;
- s: 替换,通常s命令的用法是这样的:1,2s/old/new/g,将old字符串替换成new字符
使用方法:
比如我们打开LinuxMi.py文件看下
1 import re
2 str_test='abcdefgHABC123456Linux迷'
3
4 #把正则表达式编译成对象,如果经常使用该对象,此种方式可提高一定效率
5 num_regex = re.compile(r'[0-9]')
6 zimu_regex = re.compile(r'[a-zA-z]')
7 hanzi_regex = re.compile(r'[\u4E00-\u9FA5]')
8
9 print('输入字符串:',str_test)
10 #findall获取字符串中所有匹配的字符
11 num_list = num_regex.findall(str_test)
12 print('包含的数字:',num_list)
13 zimu_list = zimu_regex.findall(str_test)
14 print('包含的字母:',zimu_list)
15 hanzi_list = hanzi_regex.findall(str_test)
16 print('包含的汉字:',hanzi_list)
我们看替换文件里面的内容,把 fill 改成 fillAA,用如下命令
1、a命令用法
主要在一行的后面加上 我们需要的东西
比如我们要在第一行增加字符串 linuxmi
[linuxmi@linux:~/Linux迷] $ sed '1 a\linuxmi' LinuxMi.py
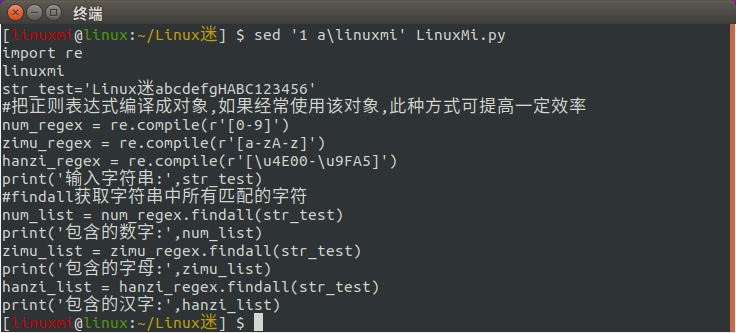
1 a是第一行的意思, 比如是2到3行 可以用 2,3 是末尾的是必然要 第二行到末尾一行可以用这个表示 2, 比如我们要在第二行到末尾一行增加 linuxmi.com,如下命令
[linuxmi@linux:~/Linux迷] sed '2, a\linuxmi.com' LinuxMi.py
效果如下
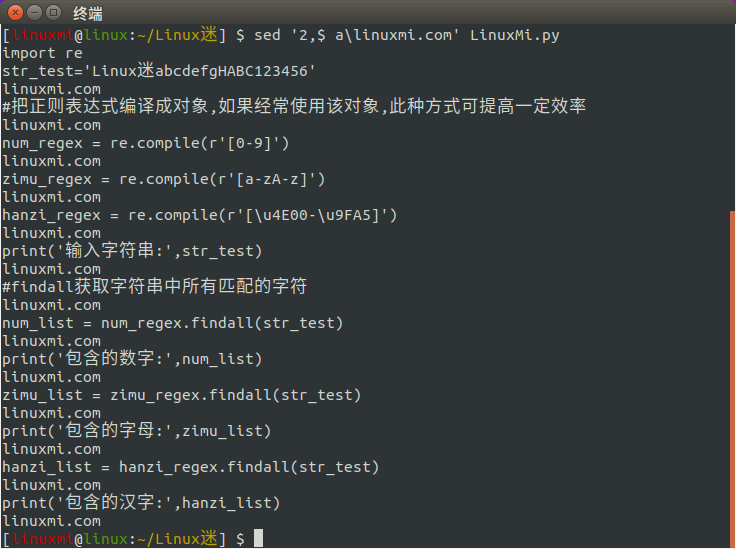
2、i命令用法
主要在一行的前面加上我们需要的东西,和a命令的效果一样。
3、c命令用法
主要是替换一行,比如
[linuxmi@linux:~/Linux迷] sed ' c\www.linuxmi.com' LinuxMi.py
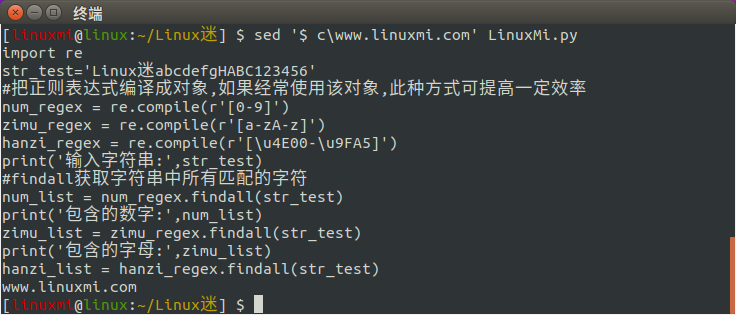
4、d命令用法
删除第5行到末尾
[linuxmi@linux:~/Linux迷] sed '5,d' LinuxMi.py

5、p命令用法
p是屏幕打印和d的用法一样
6、s命令用法
主要是替换内容,比如在文本里面把 regex 全部替换成regexp
[linuxmi@linux:~/Linux迷] $ sed 's/regex/regexp/g' LinuxMi.py
g是全部内容意思
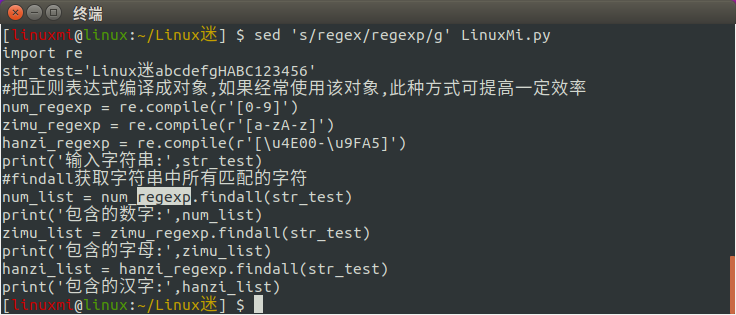
7、删除配置文件中#开头的注释行
[linuxmi@linux:~/Linux迷] $ sed '/^#/d' LinuxMi.py
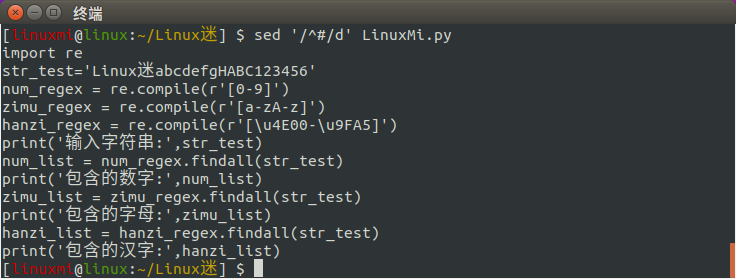
8、将所有数字替换成*
[linuxmi@linux:~/Linux迷] $ sed 's#[0-9]#*#g' LinuxMi.py
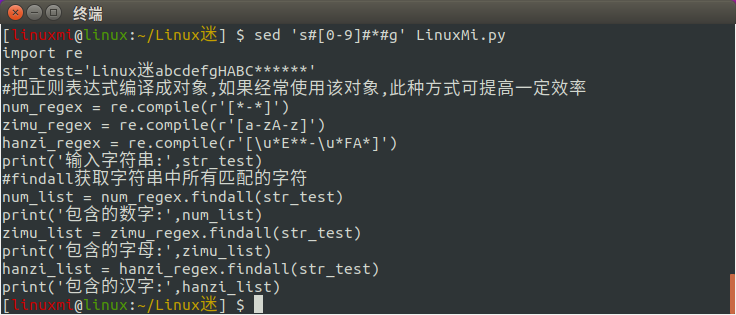
9、查询指定分行
[linuxmi@linux:~/Linux迷] $ sed -n '2p;5p' LinuxMi.py

sed可以用来自动编辑一个或多个文件,简化对文件的反复操作,编写转换程序等。暂时先这样吧。
工作中使用sed
# 查看文件的第1行到第2行
sed -n '1,2p' weipeng.log
# 查看文件的后2行
tail -2 weipeng.log
Less
线上出问题的时候,我们常用tail-n 或者tail-f或者grep或者vicat等各种命令去查看异常信息,但是日志是在不停地刷屏,tail是动态的在变的,我们往往期望从日志最后一行往前一页一页的翻页查看,从而找到异常信息,而less命令我觉得是最实用和方便的 一个日志文件中我们想从日志的最后一行往前查看 就可以用less命令 第一步:打开日志文件 lesssigma.log 第二
线上出问题的时候,我们常用tail -n 或者 tail -f 或者grep 或者 vi cat等各种命令去查看异常信息,
但是日志是在不停地刷屏,tail是动态的在变的,我们往往期望从日志最后一行往前一页一页的翻页查看,从而找到异常信息,而less命令我觉得是最实用和方便的
一个日志文件中 我们想从日志的最后一行往前查看
就可以用less命令
第一步:打开日志文件 less sigma.log
第二步:定位到日志文件的最后一行:shift+g移动到最后一行
第三步:ctrl+b往前一页一页翻页查看
参考:
1.全屏导航
ctrl + F - 向前移动一屏
ctrl + B - 向后移动一屏
ctrl + D - 向前移动半屏
ctrl + U - 向后移动半屏
2.单行导航
j - 向前移动一行
k - 向后移动一行
3.其它导航
G - 移动到最后一行
g - 移动到第一行
q / ZZ - 退出 less 命令
常见的使用方法
1、搜索
当使用命令 less file-name 打开一个文件后,可以使用下面的方式在文件中搜索。搜索时整个文本中匹配的部分会被高亮显示。
1.1向前搜索
/ : 使用一个模式进行搜索,并定位到下一个匹配的文本n : 向前查找下一个匹配的文本N : 向后查找前一个匹配的文本
1.2向后搜索
? : 使用模式进行搜索,并定位到前一个匹配的文本n : 向后查找下一个匹配的文本N : 向前查找前一个匹配的文本
2 全屏导航
ctrl + F :向前移动一屏ctrl + B :向后移动一屏ctrl + D :向前移动半屏ctrl + U :向后移动半屏
3 、单行导航
j : 向下移动一行k : 向上移动一行
4 、其它导航
G : 移动到最后一行g : 移动到第一行按空格:向下翻一页b:向上翻一页d:向下翻半页u:向上翻半页q / ZZ : 退出 less 命令
5 、编辑文件
v : 进入编辑模式,使用配置的编辑器编辑当前文件
6 标记导航
当使用 less 查看大文件时,可以在任何一个位置作标记,可以通过命令导航到标有特定标记的文本位置。
ma : 使用 a 标记文本的当前位置
a : 导航到标记 a 处
7 、浏览多个文件
方式一,传递多个参数给 less,就能浏览多个文件。less file1 file2方式二,正在浏览一个文件时,使用 :e 打开另一个文件。less file1:e file2当打开多个文件时,使用如下命令在多个文件之间切换:n - 浏览下一个文件:p - 浏览前一个文件
8 、less 版 tail -f在 Linux 动态查看日志文件常用的命令非 tail -f 莫属,其实 less 也能完成这项工作,使用 F 命令。使用 less file-name 打开日志文件,执行命令 F,可以实现类似 tail -f 的效果。
工作中使用less
# 查看后10个 拦截请求的信息
less mobileordering.api3-local-yc-nsg-f33.log | grep "拦截请求:" | tail -10
Sort
前言:
目的:逐步带你了解sort排序,解开-k参数的困惑。
困惑之处:sort -k 1.2,1.2
1.2是什么意思?1.2,1.2又是什么鬼?为什么sort -k 1.2和sort -k 1.2,1.2的排序结果不一致?
本文带你逐步解析。
一、sort语法、参数、及其注意事项
1、语法
语法:
sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件]
2、参数
参数:
-b 忽略每行前面开始出的空格字符。从第一个可见字符开始比较。
-d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
-f 排序时,忽略字符大小写.
-i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
-c 检查文件是否已经按照顺序排序。
-m 将几个排序好的文件进行合并。
-M 前面3个字母依照月份的缩写进行排序。
-n 依照数值的大小排序。
-o <输出文件> 将排序后的结果存入指定的文件。
-r 降序排列(默认是升序)。
-t <分隔字符> 指定排序时所用的栏位分隔字符。
-k field1[,field2] 按指定的列进行排序。
-u 排序后相同的行只显示一次(默认按整行进行比较)
--help 显示帮助。
--version 显示版本信息。
3、注意事项
1、排序时,默认是按每行/每个域的首字符排序,数字的优先级要大于字符的优先级
2、不指定升序还是降序时,默认是升序
vim salary.txt
google 110 5000
baidu 100 5000
guge 50 3000
sohu 100 4500
sohu 30 1500
-r降序排列
[root@127.0.0.1 ~]# sort -r salary.txt
sohu 30 1500
sohu 100 4500
guge 50 3000
google 110 5000
baidu 100 5000
-t 指定分隔符,-k 指定按哪个域进行排序
[root@127.0.0.1 ~]# sort -t ' ' -k 3 salary.txt
sohu 30 1500
guge 50 3000
sohu 100 4500
baidu 100 5000
google 110 5000
-n按数值大小排序
sort在实际排序过程中:
如果不用参数-n,则会把数字当做字符来排序
出现10 <2 的情况,要想把10 和 2 当做完整的数字来排序,需要添加-n这个选项
vim num.txt
tom 10
su 15
john 2
han 20
bell 25
jom 7
[root@127.0.0.1 ~]# sort -t ' ' -k 2 num.txt
tom 10
su 15
john 2
han 20
bell 25
jom 7
# 按照第2个域的数值大小,进行排序
[root@127.0.0.1 ~]# sort -t ' ' -n -k 2 num.txt
john 2
jom 7
tom 10
su 15
han 20
bell 25