IO流
对流的理解
流就像是一条不懂流动的河。
这个河流有什么用呢?通俗的理解,就是借助河流在不断流动的特性,将货物放到河流上,使得货物随着河流流动流到别的地方;同时在目的地,从河流上将所需的货物取出来。
模型如下:
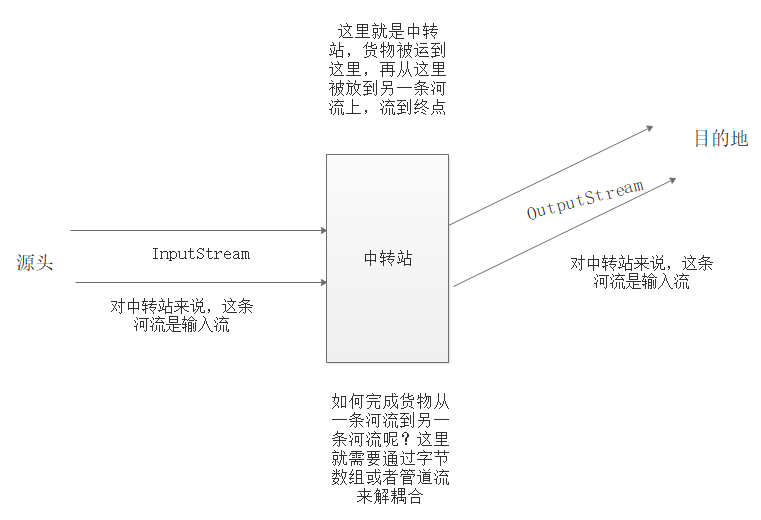
输入流就是想流向此处的河流,输出流就是从此处流向别的地方的河流。
从上面的图中,可以看出,
定义输入流时,需要先指定源头,这样就提供了推力,水流就有方向了;
定义输出流时,需要先指定目的地,这样就提供了吸力,水流就有方向了
只有这样,才能形成水流,然后,才能做数据传输和交互
输入流的read(byte b[ ])方法,其实,就是从河流中将所需的货物取出来,放到byte数组中存储。read其实就是从河流上取货物的意思。
输出流的write(byte b[ ])方法,其实,就是将货物放到河流上,这个货物就是存储在byte数组中。write,就是将货物放到河流上的意思。
输入流和输出流不是一条河流,而是两条不同的河流,他们通过byte数组来将货物进行转移。
import java.io.IOException;
import java.io.FileInputStream;
public class TestFile {
public static void main(String args[]) throws IOException {
try{
FileInputStream rf=new FileInputStream("InputFromFile.java");
int n=512; byte buffer[]=new byte[n];
while((rf.read(buffer,0,n)!=-1)&&(n>0)){
System.out.println(new String(buffer) );
}
System.out.println();
rf.close();
} catch(IOException IOe){
System.out.println(IOe.toString());
}
}
}
//------------------------------------------------------
import java.io.IOException;
import java.io.FileOutputStream;
public class TestFile {
public static void main(String args[]) throws IOException {
try {
System.out.println("please Input from Keyboard");
int count, n = 512;
byte buffer[] = new byte[n];
count = System.in.read(buffer);
FileOutputStream wf = new FileOutputStream("d:/myjava/write.txt");
wf.write(buffer, 0, count);
wf.close(); // 当流写操作结束时,调用close方法关闭流。
System.out.println("Save to the write.txt");
} catch (IOException IOe) {
System.out.println("File Write Error!");
}
}
}
从另一个角度,来加深理解InputStream的read 和 OutputStream的write。
在InputStream生成的时候,必须要指定源头。也就是说,先有源头,才能创建一个InputStream,那么InputStream在创建完成后,流中一定有数据,而InputStream所需做的就是,将数据从流中取出来。所以,read方法的作用,就是从流中取出数据,保存到byte数组中。
而OutputStream在生成的时候,必须要指定目的地。也就是说,此时OutputStream流中,没有任何数据,所以OutputStream所需做的就是,将数据放到流中,这样数据就会自动流到目的地了。所以,write方法的作用,就是将数据放到流中,这里需要将数据打包成一个集装箱---byte数组,然后才能将这个集装箱放到流中,这样数据就会自动流到目的地了。
javadoc
https://docs.oracle.com/javase/8/docs/api/java/io/InputStream.html
https://docs.oracle.com/javase/8/docs/api/java/io/OutputStream.html
对缓冲流的理解
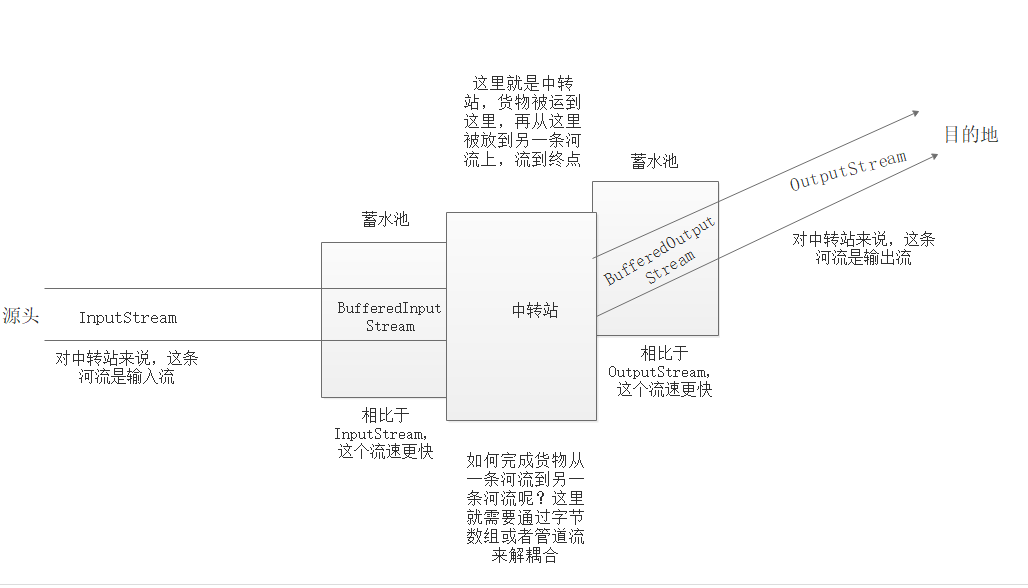
缓冲流有什么意义呢?其实很简单,是为了提高货物转移的效率。
我们可以通俗的理解,河流的速度很慢,所以运输货物的速度也比较慢,现在我们建一个蓄水池,存储一定的水,同时就存储了一批货物。当需要转移货物的时候,把我们之前存储在水上的货物,直接取出来,因为是从蓄水池取的水,所以比从河流中直接取水更快,效率更高。
同样,当我们需要货物放到河流上时,我们可以先将货物放到蓄水池中,这个放货物的速度比将货物放到河流上的速度快很多。
下面结合代码解释:当InputStream 进入蓄水池后,就会变成BufferedInputStream。记住,这个时候货物并没有发生转移,货物转移仍然需要在中转站中进行。当货物在中转站完成转移以后,将货物和水放到另一个蓄水池中,这个时候水就变成了BufferedOutputStream,相比于OutputStream,BufferedOutputStream的流速更快,放货物的速度更快。
所以缓冲流的作用其实就是:使得 取货物的速度更快,使得 放货物的速度更快。
输入流使用buffer数组样例
public static long copyLarge(final InputStream inputStream, final OutputStream outputStream, final byte[] buffer)
throws IOException {
Objects.requireNonNull(inputStream, "inputStream");
Objects.requireNonNull(outputStream, "outputStream");
long count = 0;
int n;
while (EOF != (n = inputStream.read(buffer))) {
outputStream.write(buffer, 0, n);
count += n;
}
return count;
}
/**
* Returns a new byte array of the given size.
*
* TODO Consider guarding or warning against large allocations...
*
* @param size array size.
* @return a new byte array of the given size.
* @since 2.9.0
*/
public static byte[] byteArray(final int size) {
return new byte[size];
}
字符编码
基本概念:一个字节(byte) 为 包含8个bit,可以表示256种含义
256中含义太少了,不够用。所以需要多个字节组成 一个 单元,这样就能表示 更多的含义了。比如2个字节 组成一个单元,那么就能表示256*256 = 65536种含义了。
UTF-8 是一种编码方式,每一个编码单元 由 1-3个字节组成。怎么确定某个编码单元 包含几个字节呢?规则如下:
对于UTF-8编码中的任意字节 B:
如果B的第一位为0,那么代表当前字符为单字节字符,占用一个字节的空间。0之后的所有部分(7个位)代表在Unicode中的序号。
如果B以110开头,那么代表当前字符为双字节字符,占用2个字节的空间。110之后的所有部分(5个位)加上后一个字节的除10外的部分(6个位)代表在Unicode中的序号。且第二个字节以10开头
如果B以1110开头,那么代表当前字符为三字节字符,占用3个字节的空间。1110之后的所有部分(4个位)加上后两个字节的除10外的部分(12个位)代表在Unicode中的序号。且第二、第三个字节以10开头
如果B以11110开头,那么代表当前字符为四字节字符,占用4个字节的空间。11110之后的所有部分(3个位)加上后两个字节的除10外的部分(18个位)代表在Unicode中的序号。且第二、第三、第四个字节以10开头
如果B以10开头,则B为一个多字节字符中的其中一个字节(非ASCII字符)
UTF-16每个字符都直接使用两个字节存储。当然,当存储内容过多,每个编码单元 会包含更多的字节。
所以,对于同样的一段二进制代码,不同的编码方式,解析得到的含义是完全不同的,简单的认为,解析得到的字符串是不同的。
同样,同一个字符串,按照不同的编码方式,格式化得到的一段二进制代码也是完全不同的。
Encode & decode & character & byte
encode:从字符到字节
decode:从字节到字符
一个字节:8个bit
一个字符:2个字节(具体看字符集)
客户端与服务器端传输数据:默认iso8859-1
客户端将数据按照iso8859-1字符集,将字符进行编码,成为字节
按照http协议将数据传输到服务器端,
服务器端按照iso8859-1字符集对接收的字节进行解码,成为字符
javase里的String类的byte[]getBytes(String charsetName) throws UnsupportedEncodingException方法,就是将字符串按照参数charsetName,对字符串进行编码为字节数组。
String的构造器方法:new String(byte[] bytes, String charsetName),会对bytes字节数组,按照参数charsetName进行解码为字符串,然后显示。
比如:现在有字符串A= "中国你好",是iso8859-1编码的,因为iso8859-1不支持中文,所以按照iso8859-1解码成字符后肯定是乱码,我们想要按照utf-8
字符集进行显示字符串A,应该怎么搞?
方法很简单,首先用iso8859-1对字符串A编码为字节数组,然后按照utf-8进行对字节数组进行解码为字符串B,在tuf-8的语言环境下,字符串B就会显示为 中国你好。
用java api实现的话,
String A="中国";
byte[] a = A.getBytes("iso8859-1");
String B = new String(a,"UTF-8");
System.out.println(B);
字符流Writer/Reader
Java中字符是采用Unicode标准,一个字符是16位,即一个字符使用两个字节来表示。为此,JAVA中引入了处理字符的流。
javadoc
https://docs.oracle.com/javase/8/docs/api/java/io/Reader.html
https://docs.oracle.com/javase/8/docs/api/java/io/Writer.html
InputStream与Reader差别 OutputStream与Writer差别
InputStream和OutputStream类处理的是字节流,数据流中的最小单位是字节(8个bit)
Reader与Writer处理的是字符流,在处理字符流时涉及了字符编码的转换问题.。
所以,同样是read方法,InputStream read后,是放在一个byte[]数组中存储,而Reader read后,是放到一个char[] 数组中存储
同样是write方法,OutputStream 是将一个byte[] 数组中内容 放出去,而Writer write时,是将char[] 数组中的内容放出去。
其实,形成的Reader流,流中的数据,是以char的形式存在的;而形成的InputStream流,流中的数据,是以byte的形式存在的。
而我们知道,想要将一个对象,转换成byte,就涉及到字符编码的问题---Charset(StandardCharsets.UTF_8);
而将一个对象,转为char,此时并不会涉及到Charset。因为char本身就是使用字符集编码后的结果。
因此,如果想要将Reader转换成InputStream,必须要指定字符集---Charset(StandardCharsets.UTF_8)。同样,如果想要将InputStream转换为Reader,也需要指定字符集编码---Charset。
InputStreamReader
An InputStreamReader is a bridge from byte streams to character streams: It reads bytes and decodes them into characters using a specified charset. The charset that it uses may be specified by name or may be given explicitly, or the platform's default charset may be accepted.
Each invocation of one of an InputStreamReader's read() methods may cause one or more bytes to be read from the underlying byte-input stream. To enable the efficient conversion of bytes to characters, more bytes may be read ahead from the underlying stream than are necessary to satisfy the current read operation.
For top efficiency, consider wrapping an InputStreamReader within a BufferedReader. For example:
BufferedReader in
= new BufferedReader(new InputStreamReader(System.in));
| Constructor and Description |
|---|
InputStreamReader(InputStream in)Creates an InputStreamReader that uses the default charset. |
InputStreamReader(InputStream in, Charset cs)Creates an InputStreamReader that uses the given charset. |
InputStreamReader(InputStream in, CharsetDecoder dec)Creates an InputStreamReader that uses the given charset decoder. |
InputStreamReader(InputStream in, String charsetName)Creates an InputStreamReader that uses the named charset. |
javadoc
https://docs.oracle.com/javase/8/docs/api/java/io/InputStreamReader.html
管道流
模型:
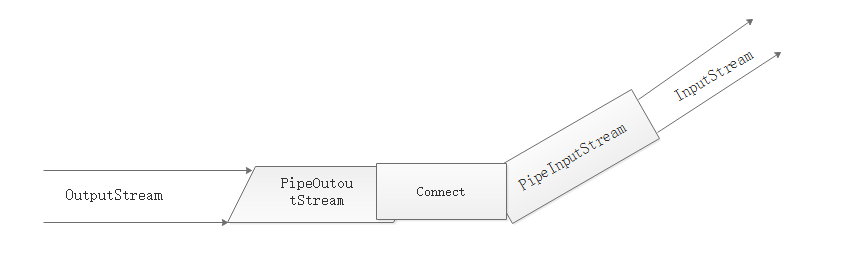
实验1
在线程Sender中向管道流中写入一个字符串,写入后关闭该管道流;在线程Reciever中读取该字符串。
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
try {
//创建管道流
PipedOutputStream pos = new PipedOutputStream();
// 实现PipedOutputStream与PipedInputStream connect上了
PipedInputStream pis = new PipedInputStream(pos);
//创建线程对象
Sender sender = new Sender(pos);
Reciever reciever = new Reciever(pis);
//运行子线程
executorService.execute(sender);
executorService.execute(reciever);
} catch (IOException e) {
e.printStackTrace();
}
}
static class Sender extends Thread {
private PipedOutputStream pos;
public Sender(PipedOutputStream pos) {
super();
this.pos = pos;
}
@Override
public void run() {
try {
String s = "This is a good day. 今天是个好天气。";
System.out.println("Sender:" + s);
byte[] buf = s.getBytes();
// 将货物放到PipedOutputStream上
pos.write(buf, 0, buf.length);
pos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
static class Reciever extends Thread {
private PipedInputStream pis;
public Reciever(PipedInputStream pis) {
super();
this.pis = pis;
}
@Override
public void run() {
try {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buf = new byte[1024];
int len = 0;
// 将货物从PipedInputStream上取出
while ((len = pis.read(buf)) != -1) {
// 将从PipedInputStream上取到的货物 又放到了ByteArrayOutputStream上
baos.write(buf, 0, len);
}
byte[] result = baos.toByteArray();
String s = new String(result, 0, result.length);
System.out.println("Reciever:" + s);
} catch (IOException e) {
e.printStackTrace();
}
}
}
实验2
从d:\input.txt 读取内容,通过管道流,最后存储到d:\output.txt
public static void main(String[] args) {
try {
PipedInputStream pis = new PipedInputStream();
PipedOutputStream pos = new PipedOutputStream(pis);
Sender sender = new Sender(pos);
Reciever reciever = new Reciever(pis);
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(sender);
executorService.execute(reciever);
} catch (IOException e) {
e.printStackTrace();
}
}
static class Sender extends Thread {
private PipedOutputStream pos = null;
public Sender(PipedOutputStream pos) {
this.pos = pos;
}
@Override
public void run() {
try {
// 将d:\\input.txt中的内容 放到 PipedOutputStream上
FileInputStream fis = new FileInputStream("d:\\input.txt");
byte[] buf = new byte[1024];
int len = 0;
while ((len = fis.read(buf)) != -1) {
pos.write(buf, 0, len);
}
pos.flush();
pos.close();
fis.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
static class Reciever extends Thread {
private PipedInputStream pis = null;
public Reciever(PipedInputStream pis) {
this.pis = pis;
}
@Override
public void run() {
try {
FileOutputStream fos = new FileOutputStream("d:\\output.txt");
byte[] buf = new byte[1024];
int len = 0;
while ((len = pis.read(buf)) != -1) {
// 将从PipedInputStream 上获取到的货物 放到 FileOutputStream上
fos.write(buf, 0, len);
}
fos.flush();
fos.close();
pis.close();
System.out.println("receive end");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
在使用管道流的时候,需要注意以下要点:
第一,管道流仅用于多个线程之间传递信息,若用在同一个线程中可能会造成死锁;
第二,管道流的输入输出是成对的,一个输出流只能对应一个输入流,使用构造函数或者connect函数进行连接;
第三,一对管道流包含一个缓冲区,其默认值为1024个字节,若要改变缓冲区大小,可以使用带有参数的构造函数;
第四,管道的读写操作是互相阻塞的,当缓冲区为空时,读操作阻塞;当缓冲区满时,写操作阻塞;
第五,管道依附于线程,因此若线程结束,则虽然管道流对象还在,仍然会报错“read dead end”;
第六,管道流的读取方法与普通流不同,只有输出流正确close时,输出流才能读到-1值
InputStream众多实现类
我们知道,InputStream有很多实现类,那么这些实现类有什么区别?分别用于什么场景呢?
其实很简单,我们知道,在我们创建InputStream时,必须先指定源头。因此,如果源头是文件,那么就使用FileInputStream;如果源头是字节数组,那么就是ByteArrayInputStream。
FileInputStream :源头是文件,可以看其构造方法
ByteArrayInputStream:源头是字节数组,可以看其构造方法
OutputStream众多实现类
OutputStream也有众多实现类,那么这些实现类有什么区别?分别用于什么场景呢?
其实很简单,我们知道,在我们创建OutputStream时,必须先指定目的地。因此,如果目的地是文件,那么就使用FileOutputStream。
Path & File
Path
javadoc
https://docs.oracle.com/javase/8/docs/api/java/nio/file/Path.html
An object that may be used to locate a file in a file system. It will typically represent a system dependent file path.
A Path represents a path that is hierarchical and composed of a sequence of directory and file name elements separated by a special separator or delimiter. A root component, that identifies a file system hierarchy, may also be present. The name element that is farthest from the root of the directory hierarchy is the name of a file or directory. The other name elements are directory names. A Path can represent a root, a root and a sequence of names, or simply one or more name elements. A Path is considered to be an empty path if it consists solely of one name element that is empty. Accessing a file using an empty path is equivalent to accessing the default directory of the file system. Path defines the getFileName, getParent, getRoot, and subpath methods to access the path components or a subsequence of its name elements.
In addition to accessing the components of a path, a Path also defines the resolve and resolveSibling methods to combine paths. The relativize method that can be used to construct a relative path between two paths. Paths can be compared, and tested against each other using the startsWith and endsWith methods.
This interface extends Watchable interface so that a directory located by a path can be registered with a WatchService and entries in the directory watched.
WARNING: This interface is only intended to be implemented by those developing custom file system implementations. Methods may be added to this interface in future releases.
Accessing Files
Paths may be used with the Files class to operate on files, directories, and other types of files. For example, suppose we want a BufferedReader to read text from a file "access.log". The file is located in a directory "logs" relative to the current working directory and is UTF-8 encoded.
Path path = FileSystems.getDefault().getPath("logs", "access.log");
BufferedReader reader = Files.newBufferedReader(path, StandardCharsets.UTF_8);
Interoperability
Paths associated with the default provider are generally interoperable with the java.io.File class. Paths created by other providers are unlikely to be interoperable with the abstract path names represented by java.io.File. The toPath method may be used to obtain a Path from the abstract path name represented by a java.io.File object. The resulting Path can be used to operate on the same file as the java.io.File object. In addition, the toFile method is useful to construct a File from the String representation of a Path.
resolve
public static void main(String[] args) throws IOException {
// 获得一个relative path
Path workRelative = Paths.get("work");
// 获得一个absolute path
Path testAbsolute = Paths.get("D:", "test");
Path resolve = testAbsolute.resolve(workRelative);
System.out.println(resolve); // D:\test\work
}
It is very common to combine or resolve paths. The call p.resolve(q) returns a path according to these rules:
•If q is absolute, then the result is q.
•Otherwise, the result is “p then q,” according to the rules of the file system
resolveSibling
public static void main(String[] args) throws IOException {
// 获得一个relative path
Path workRelative = Paths.get("work");
// 获得一个absolute path
Path testAbsolute = Paths.get("D:", "test");
System.out.println(testAbsolute); // D:\test
Path resolve = testAbsolute.resolve(workRelative);
System.out.println(resolve); // D:\test\work
Path resolveSibling = testAbsolute.resolveSibling(workRelative);
System.out.println(resolveSibling); // D:\work
}
normalize & toAbsolutePath
The normalize method removes any redundant . and .. components (or whatever the file system may deem redundant).
For example, normalizing the path /home/harry/../fred/./input.txt yields /home/fred/input.txt.
The toAbsolutePath method yields the absolute path of a given path, starting at a root component,
such as /home/fred/input.txt or c:\Users\fred\input.txt.
The Path interface has many useful methods for taking paths apart. This code sample shows some of the most useful ones:
Path p = Paths.get("/home", "fred", "myprog.properties");
Path parent = p.getParent(); // the path /home/fred
Path file = p.getFileName(); // the path myprog.properties
Path root = p.getRoot(); // the path /
Paths
javadoc
https://docs.oracle.com/javase/8/docs/api/java/nio/file/Paths.html
This class consists exclusively of static methods that return a Path by converting a path string or URI.
Method Summary
| Modifier and Type | Method and Description |
|---|---|
static Path | get(String first, String... more)Converts a path string, or a sequence of strings that when joined form a path string, to a Path. |
static Path | get(URI uri)Converts the given URI to a Path object. |
Path absolute = Paths.get("/home", "harry");
Path relative = Paths.get("myprog", "conf", "user.properties");
public static Path get(String first,
String... more)
Converts a path string, or a sequence of strings that when joined form a path string, to a Path. If more does not specify any elements then the value of the first parameter is the path string to convert. If more specifies one or more elements then each non-empty string, including first, is considered to be a sequence of name elements (see Path) and is joined to form a path string. The details as to how the Strings are joined is provider specific but typically they will be joined using the name-separator as the separator.
For example, if the name separator is "/" and getPath("/foo","bar","gus") is invoked, then the path string "/foo/bar/gus" is converted to a Path. A Path representing an empty path is returned if first is the empty string and more does not contain any non-empty strings.
Files
javadoc
https://docs.oracle.com/javase/8/docs/api/java/nio/file/Files.html
This class consists exclusively of static methods that operate on files, directories, or other types of files.
In most cases, the methods defined here will delegate to the associated file system provider to perform the file operations.
reading & writing file
The Files class makes quick work of common file operations.
For example, you can easily read the entire contents of a file:
byte[] bytes = Files.readAllBytes(path);
If you want to read the file as a string, call readAllBytes followed by
String content = new String(bytes, charset);
But if you want the file as a sequence of lines, call
List lines = Files.readAllLines(path, charset);
Conversely, if you want to write a string, call
Files.write(path, content.getBytes(charset));
To append to a given file, use
Files.write(path, content.getBytes(charset), StandardOpenOption.APPEND);
You can also write a collection of lines with
Files.write(path, lines);
These simple methods are intended for dealing with text files of moderate length. If your files are large or binary, you can still use the familiar input/output streams or readers/writers:
InputStream in = Files.newInputStream(path);
OutputStream out = Files.newOutputStream(path);
Reader in = Files.newBufferedReader(path, charset);
Writer out = Files.newBufferedWriter(path, charset);
create file & directory
To create a new directory, call
Files.createDirectory(path);
All but the last component in the path must already exist.
To create intermediate directories as well, use
Files.createDirectories(path);
You can create an empty file with
Files.createFile(path);
The call throws an exception if the file already exists. The check for existence and creation are atomic. If the file doesn’t exist, it is created before anyone else has a chance to do the same.
Copying, Moving, and Deleting Files
To copy a file from one location to another, simply call
Files.copy(fromPath, toPath);
To move the file (that is, copy and delete the original), call
Files.move(fromPath, toPath);
The copy or move will fail if the target exists. If you want to overwrite an existing target, use the REPLACE_EXISTING option. If you want to copy all file attributes, use the COPY_ATTRIBUTES option. You can supply both like this:
Files.copy(fromPath, toPath, StandardCopyOption.REPLACE_EXISTING, StandardCopyOption.COPY_ATTRIBUTES);
You can specify that a move should be atomic. Then you are assured that either the move completed successfully, or the source continues to be present. Use the ATOMIC_MOVE option:
Files.move(fromPath, toPath, StandardCopyOption.ATOMIC_MOVE);
You can also copy an input stream to a Path, which just means saving the input stream to disk. Similarly, you can copy a Path to an output stream. Use the following calls:
Files.copy(inputStream, toPath);
Files.copy(fromPath, outputStream);
getting file information
The following static methods return a boolean value to check a property of a path:
•exists
•isHidden
•isReadable, isWritable, isExecutable
•isRegularFile, isDirectory, isSymbolicLink
The size method returns the number of bytes in a file.
long fileSize = Files.size(path);
All file systems report a set of basic attributes, encapsulated by the BasicFileAttributes interface, which partially overlaps with that information. The basic file attributes are
•The times at which the file was created, last accessed, and last modified, as instances of the class java.nio.file.attribute.FileTime
•Whether the file is a regular file, a directory, a symbolic link, or none of these
•The file size
•The file key—an object of some class, specific to the file system, that may or may not uniquely identify a file
To get these attributes, call
BasicFileAttributes attributes = Files.readAttributes(path, BasicFileAttributes.class);
Visiting Directory Entries
The static Files.list method returns a Stream that reads the entries of a directory. The directory is read lazily, making it possible to efficiently process directories with huge numbers of entries.
Since reading a directory involves a system resource that needs to be closed, you should use a try block:
try (Stream entries = Files.list(pathToDirectory))
{
. . .
}
The list method does not enter subdirectories. To process all descendants of a directory, use the Files.walk method instead.
try (Stream entries = Files.walk(pathToRoot))
{
// Contains all descendants, visited in depth-first order
}
Here is a sample traversal of the unzipped src.zip tree:
java
java/nio
java/nio/DirectCharBufferU.java
java/nio/ByteBufferAsShortBufferRL.java
java/nio/MappedByteBuffer.java
. . .
java/nio/ByteBufferAsDoubleBufferB.java
java/nio/charset
java/nio/charset/CoderMalfunctionError.java
java/nio/charset/CharsetDecoder.java
java/nio/charset/UnsupportedCharsetException.java
java/nio/charset/spi
java/nio/charset/spi/CharsetProvider.java
java/nio/charset/StandardCharsets.java
java/nio/charset/Charset.java
. . .
java/nio/charset/CoderResult.java
java/nio/HeapFloatBufferR.java
. . .
As you can see, whenever the traversal yields a directory, it is entered before continuing with its siblings.
You can limit the depth of the tree that you want to visit by calling Files.walk(pathToRoot, depth).
This code fragment uses the Files.walk method to copy one directory to another:
Files.walk(source).forEach(p ->
{
try
{
Path q = target.resolve(source.relativize(p));
if (Files.isDirectory(p))
Files.createDirectory(q);
else
Files.copy(p, q);
}
catch (IOException ex)
{
throw new UncheckedIOException(ex);
}
});