多核 & 多线程
多核
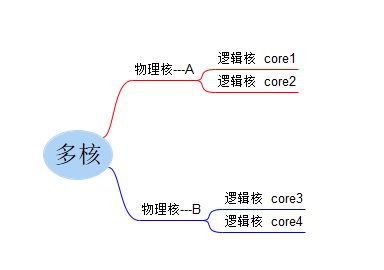
CPU( CentralProcessingUnit): 中央处理单元,CPU不等于物理核,更不等于逻辑核。
物理核(physical core/processor): 可以看的到的,真实的cpu核,有独立的电路元件以及L1,L2缓存,可以独立地执行指令。
逻辑核( logical core/processor,LCPU): 在同一个物理核内,逻辑层面的核。
多个物理CPU,CPU通过总线进行通信,效率比较低。

多核CPU,不同的核通过L2 cache进行通信,存储和外设通过总线与CPU通信
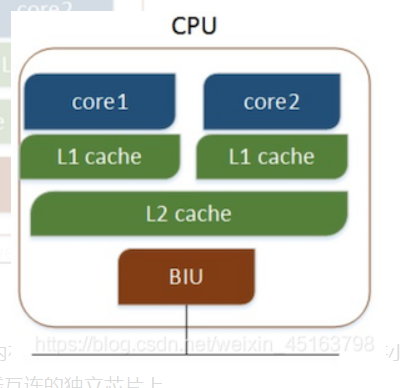
cpu的缓存
CPU缓存是位于CPU与内存之间的临时数据交换器,它的容量比内存小的多但是交换速度却比内存要快得多。CPU缓存一般直接跟CPU芯片集成或位于主板总线互连的独立芯片上。
随着多核CPU的发展,CPU缓存通常分成了三个级别:L1,L2,L3。级别越小越接近CPU,所以速度也更快,同时也代表着容量越小。L1 是最接近CPU的, 它容量最小(例如:32K),速度最快,每个核上都有一个 L1 缓存,L1 缓存每个核上其实有两个 L1 缓存, 一个用于存数据的 L1d Cache(Data Cache),一个用于存指令的 L1i Cache(Instruction Cache)。L2 缓存 更大一些(例如:256K),速度要慢一些, 一般情况下每个核上都有一个独立的L2 缓存; L3 缓存是三级缓存中最大的一级(例如3MB),同时也是最慢的一级, 在同一个CPU插槽之间的核共享一个 L3 缓存。
读取数据过程。就像数据库缓存一样,首先在最快的缓存中找数据,如果缓存没有命中(Cache miss) 则往下一级找, 直到三级缓存都找不到时,向内存要数据。一次次地未命中,代表取数据消耗的时间越长。
计算过程。程序以及数据被加载到主内存;指令和数据被加载到CPU的高速缓;CPU执行指令,把结果写到高速缓存;高速缓存中的数据写回主内存
进程和线程
进程是资源分配的最小单位,一个程序有至少一个进程。
线程是程序执行的最小单位。一个进程有至少一个线程。
进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵。
而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多。
线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(IPC)进行。不过如何处理好同步与互斥是编写多线程程序的难点。
多进程程序更健壮,多线程程序只要有一个线程死掉,整个进程也死掉了,而一个进程死掉并不会对另外一个进程造成影响,因为进程有自己独立的地址空间。
CPU core 与 进程、线程的关系
是一对多的关系。我们举一个例子,家里只有1个水管,出水量2m3/s。现在有以下几个地方需要用水:洗衣机2m3/s、 洗澡的花洒2m3/s、洗碗机2m3/s。
因为出水量是固定的2m^3/s,只能给3个其中一个使用;因此,只能让洗衣机运行一会儿,停掉,接着让洗澡的花洒运行一会儿,再停掉;接着再给洗碗机运行一会儿。
也就是说,在某个时间点,cpu core被某个线程独占;但在较长的时间段来看,cpu core是轮流给不同的线程使用。
Goroutines
Go runtime : when a Go program starts,creates a number of threads and launches a single goroutine to run your program.
Go runtime scheduler: assign all of the goroutines created by your program to threads automatically
在Java中,java-level thread 和 operating system-level thread,是一一映射 和 一一绑定的。
但是在Go中,goroutine 和 operating system-level thread,是多对一的关系。
A goroutine is launched by placing the go keyword before a function invocation.
Just like any other function, you can pass it parameters to initialize its state. However,any values returned by the function are ignored.
func process(val int) int {
// do something with val
return 0
}
func runThingConcurrently(in <-chan int, out chan<- int) {
go func() {
for val := range in {
result := process(val)
out <- result
}
}()
}
how to launch goroutines ?
with a closure that wraps business logic
go routinue 和 channel是什么关系?分别扮演什么角色?
数据的处理过程是:take data —> transform it —> output result
其中,go routinue主要用于transform it,而take data 和 output result,全部需要依赖channel。go routinue需要的数据,需要从channel中取;go routinue输出的结果,需要输出到channel中。
Channel
goroutines communicate using channels
create & pass
ch := make(chan int)
Like maps, channels are reference types. When you pass a channel to a function, you are really passing a pointer to the channel. Also like maps and slices, the zero value for a channel is nil.
Reading, Writing
先确定channel variable,箭头放左边,表示从channel variable中读数据;箭头放右边,表示向channel variable 中写数据。
// You read from a channel by placing the <- operator to the left of the channel variable,
a := <- ch
// write a value to a channel by placing the <- operator to the right of the channel variable
ch <- b
先确定channel variable,将channel variable 看成一个管道,根据箭头的方向,就知道数据是向channel variable中流入;还是从channel variable中流出。
同样的道理,在声明一个channel variable or channle field时:
我们也是先确定chan keyword,然后根据箭头的方向,判断,数据从chan中流出,还是向chan中流入
use an arrow before the chan keyword (ch <-chan int) to indicate that the goroutine only
reads from the channel
and use an arrow after the chankeyword (ch chan<- int) to indicate that the goroutine onlywrites to the channel.
Each value written to a channel can only be read once. If multiple goroutines are reading from the same channel, a value written to the channel will only be read by one of them
Buffering
By default channels are unbuffered.
Every write to an open, unbuffered channel causes the writing goroutine to pause until another goroutine reads from the same channel.
Likewise, a read from an open, unbuffered channel causes the reading goroutine to pause until another goroutine writes to the same channel.
This means you cannot write to or read from an unbuffered channel without at least two concurrently running goroutines
Go also has buffered channels.
These channels buffer a limited number of writes without blocking.
If the buffer fills before there are any reads from the channel, subsequent write to the channel pause the writing goroutine until the channel is read.
Just as writing to channel with a full buffer blocks, reading from a channel with an empty buffer also blocks
A buffered channel is created by specifying the capacity of the buffer when creating the channel:
ch := make(chan int,10)
The built-in functions len and cap return information about a buffered channel. Use len to find out how many values are currently in the buffer and use cap to find out the maximum buffer size. The capacity of the buffer cannot be changed.
for-range & channel
// You can also read from a channel using a for-range loop
for v := range ch {
fmt . Println ( v )
}
The loop continues until the channel is closed, or until a break or return statement is reached
channel中若要使用for range进行遍历操作,channel必须首先要进行关闭操作的。
func main() {
in := make(chan int, 10)
for i := 0; i < 10; i++ {
in <- i
}
go func() {
for v := range in {
fmt.Println(v)
}
fmt.Println("go routinue end")
}()
time.Sleep(5*time.Second)
close(in)
fmt.Println("main closed channel")
time.Sleep(2*time.Second)
fmt.Println("main end")
}
执行结果如下:
0
1
2
3
4
5
6
7
8
9
main closed channel
go routinue end
main end
啥意思呢?
就是说,对一个channel,进行for-range,如果不事先关闭这个channel,那么for-range会一致block。当我们事先,将channel关闭,再进行for-range,这样,当channel中的元素被遍历完成后,会自动退出for-range
Closing a Channel
how to close a channel?
invoke close function:
close(ch)
Once a channel is closed, any attempts to write to the channel or close the channel again will panic.
Interestingly, attempting to read from a closed channel always succeeds.
If the channel is buffered and there are values that haven’t been read yet, they will be returned in-order.
If the channel is unbuffered or the buffered channel has no more values, the zero value for the channel’s type is returned
how do we tell the difference between a zero value that was written and a zero value that was returned because channel is closed?
we use the comma ok idiom to detect whether a channel has been closed or not.
v , ok := <- ch
If ok is set to true, then the channel is open. If it is set to false, the channel is closed
Avoid cause panic
As mentioned earlier, the standard pattern is to make the writing goroutine responsible for closing the channel when there’s nothing left to write.
When multiple goroutines are writing to the same channel, this becomes more complicated, as calling close twice on the same channel causes a panic.
Furthermore, if you close a channel in one goroutine, a write to the channel in another goroutine triggers a panic as well.
The way to address this is to use a sync.WaitGroup
Channel type
// contains data of type int
ch1 := make(chan int)
// contains data of type struct{}
ch2 := make(chan struct{})
// contains data of type []string
ch3 := make(chan []string)
Select statement
The select keyword allows a goroutine to read from or writeto one of a set of multiple channels. It looks a great deal like a blank switch statement:
select {
case v := <-ch:
fmt.Println(v)
case v := <-ch2:
fmt.Println(v)
case ch3 <- x:
fmt.Println("wrote", x)
case <-ch4:
fmt.Println("got value on ch4, but ignored it")
}
Each case in a select is a read or a write to a channel.
If a read or write is possible for a case, it is executed along with the body of the case.
Like a switch, each case in a select creates its own block.
What happens if multiple cases have channels that can be read or written?
The select algorithm is simple: it picks randomly from any of its cases that can go forward; order is
unimportant.
This is very different from a switch statement, which always chooses the first case that resolves to true.
It also cleanly resolves the starvation problem, as no case is favored over another and all are checked at the same time.
select resolve deadlock
Another advantage of select choosing at random is that it prevents one of the most common causes of deadlocks: acquiring locks in an inconsistent order.
If you have two goroutines that both access the same two channels, they must be accessed in the same order in both goroutines, or they will deadlock.
This means that neither one can proceed because they are waiting on each other. If every goroutine in your Go application is deadlocked, the Go runtime kills your program.
deadLock goroutine
package main
import "fmt"
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
v := 1
ch1 <- v
v2 := <-ch2
fmt.Println(v, v2)
}()
v := 2
ch2 <- v
v2 := <-ch1
fmt.Println(v, v2)
}
输出
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
E:/lagouRes/Go/goBorn/goconcueernt/src/wpchannel/wpdeadlock.go:18 +0xaf
goroutine 19 [chan send]:
main.main.func1()
E:/lagouRes/Go/goBorn/goconcueernt/src/wpchannel/wpdeadlock.go:11 +0x38
created by main.main
E:/lagouRes/Go/goBorn/goconcueernt/src/wpchannel/wpdeadlock.go:9 +0x97
Process finished with the exit code 2
Remember that our main is running on a goroutine that is launched at startup by the Go runtime.
The goroutine that we launch cannot proceed until ch1 is read,
and the main goroutine cannot proceed until ch2 is read.
针对上面的问题,怎么修改呢?
很简单,我们只需要调换一行代码的位置,就可以了
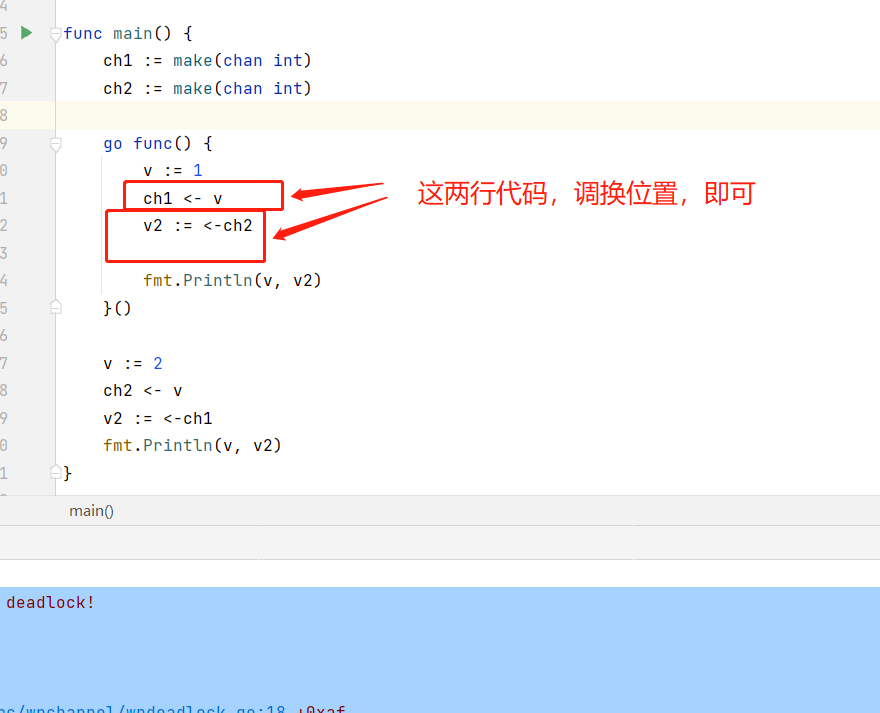
package main
import "fmt"
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
v := 1
v2 := <-ch2
ch1 <- v
fmt.Println("sole goroutine",v, v2)
}()
v := 2
ch2 <- v
v2 := <-ch1
fmt.Println("main gotoutine",v, v2)
}
输出
main gotoutine 2 1
sole goroutine 1 2
还有另一种方式,解决deadLock,就是使用select
package main
import "fmt"
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
v := 1
ch1 <- v
v2 := <-ch2
fmt.Println("sole goroutine", v, v2)
}()
v := 2
var v2 int
select {
case ch2 <- v:
case v2 = <-ch1:
}
fmt.Println("main gotoutine", v, v2)
}
输出
main gotoutine 2 1
because a select checks if any of its cases can proceed, the deadlock is avoided.
The goroutine that we launched wrote the value 1 into ch1 , so the read from ch1 into v2 in the main goroutine is able to succeed.
如果有多个case都可以运行,select会随机公平地选出一个执行。其他不会执行。
select default
我们在看下select-default
The following code does not wait if there’s no value to read in ch; it immediately executes the body of the default
:
package main
import "fmt"
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
v := 1
ch1 <- v
v2 := <-ch2
fmt.Println("sole goroutine", v, v2)
}()
v := 2
select {
case ch2 <- v:
fmt.Println("main gotoutine write to ch2", v)
default:
fmt.Println("no goroutine read from ch2")
}
}
输出
no goroutine read from ch2
for loop embedded select
for {
select {
case <-done:
return
case v := <-ch:
fmt.Println(v)
}
}
When using a for-select loop, you must include a way to exit the loop
Practise & Pattern
pass the value as a parameter to the goroutine
Most of the time, the closure that you use to launch a goroutine has no parameters.
Instead, it captures values from the environment where it was declared.
But in some situation,we need pass the value as a parameter to the goroutine.
package main
import "fmt"
func main() {
a := []int{2, 4, 6, 8, 10}
ch := make(chan int, len(a))
for _, v := range a {
go func(val int) {
ch <- val * 2
}(v)
}
for i := 0; i < len(a); i++ {
fmt.Println(<-ch)
}
}
输出
4
8
12
16
20
Any time your goroutine uses a variable whose value might change, pass the current value of the variable into the goroutine.
Always Cleanup Your Goroutines
Whenever you launch a goroutine function, you must make sure that it will eventually exit. Unlike variables, the Go runtime can’t detect that a goroutine will never be used again.
If a goroutine doesn’t exit, the scheduler will still periodically give it time to do nothing, which slows down your program. This is called a goroutine leak
package main
import "fmt"
func main() {
for i := range countTo(10) {
if i>5 {
break
}
fmt.Println(i)
}
}
func countTo(max int) <-chan int {
ch := make(chan int)
go func() {
for i := 0; i < max; i++ {
ch <- i
}
fmt.Println("-----------")
close(ch)
}()
return ch
}
输出
0
1
2
3
4
5
上面的这个例子, we exit the loop early, the goroutine blocks forever, waiting for a value to be read from the channel:
也就是说,countTo函数中的写goroutinue,一直被阻塞,因为,没有其他的goroutinue从这个channel中读取值,所以,countTo函数中的写goroutinue,会一直处于阻塞状态
signal a goroutine that it’s time to stop processing—The Done Channel Pattern
The done channel pattern provides a way to signal a goroutine that it’s time to stop processing.
It uses a channel to signal that it’s time to exit.
Let’s look at an example, where we pass the same data to multiple functions, but only want the result from the fastest function:
func searchData(s string, searchers []func(string) []string) []string {
done := make(chan struct{})
result := make(chan []string)
for _, searcher := range searchers {
go func(searcherVal func(string) []string) {
select {
case result <- searcherVal(s):
case <-done:
}
}(searcher)
}
r := <-result
close(done)
return r
}
The select statements in the worker goroutines wait for either a write on the result channel (when the searcher function returns) or a read on the done channel.
Remember that a read on an open channel pauses until there is data available
and that a read on a closed channel always returns the zero value for the channel.
This means that the case that reads from done will stay paused until done is closed.
In searchData, we read the first value written to result, and then we close done.
This signals to the goroutines that they should exit, preventing them from leaking.
Terminate a Goroutine — Return Cancel Function
package main
import (
"fmt"
)
func main() {
ch, cancel := countTo(10)
for i := range ch {
if i > 5 {
break
}
fmt.Println(i)
}
cancel()
fmt.Println("kkkkkkkkkkkkkkkk")
}
func countTo(max int) (<-chan int, func()) {
ch := make(chan int)
done := make(chan struct{})
cancel := func() {
close(done)
}
go func() {
for i := 0; i < max; i++ {
select {
case <-done:
fmt.Println("prepare exit,i:",i)
return
case ch <- i:
fmt.Println("writed to channel,i:",i)
}
}
}()
return ch, cancel
}
输出
writed to channel,i: 0
0
1
writed to channel,i: 1
writed to channel,i: 2
2
3
writed to channel,i: 3
writed to channel,i: 4
4
5
writed to channel,i: 5
writed to channel,i: 6
kkkkkkkkkkkkkkkk
Process finished with the exit code 0
The Diffrence for The Done Channel Pattern & Cancel Function
The Done Function— 在外部创建一个done channel,将这个done channel pass into goroutinue。外部直接操作这个done channel,来实现goroutinue 中代码结束
The Cancel Funtion—在function内部创建一个done channel,然后返回一个cancel function,外部直接调用这个cancel function,是实现goroutinue中代码结束
So what is the proper use of a buffered channel
To sum it up in a single sentence:
Buffered channels are useful when you know how many goroutines you have launched, want to limit the number of goroutines you will launch, or want to limit the amount of work that is queued up.
Buffered channels work great when you want to either gather data back from a set of goroutines that you have launched or when you want to limit concurrent usage. They are also helpful for managing the amount of work a system has queued up,preventing your services from falling behind and becoming overwhelmed.
一个经典的例子:现在有10个任务,我需要使用多线程加快处理,等10个任务都处理好了,将所有任务处理好的结果,收集起来,再返回结果。
func processChannel(ch chan int) []int {
const conc = 10
results := make(chan int, conc)
for i := 0; i < conc; i++ {
go func() { results <- process(v) }()
}
var out []int
for i := 0; i < conc; i++ {
out = append(out, <-results)
}
return out
}
We know exactly how many goroutines we have launched, and we want each goroutine to exit as soon as it finishes its work.
This means we can create a buffered channel with one space for each launched goroutine, and have each goroutine write data to this goroutine without blocking.
We can then loop over the buffered channel, reading out the values as they are written.
When all of the values have been read, we return the results, knowing that we aren’t leaking any goroutines.
Backpressure
We can use a buffered channel and a select statement to limit the number of simultaneous requests in a system:
我们可以利用buffered channel,构建一个简易的限流工具,如下:
type PressureGauge struct {
ch chan struct{}
}
func New(limit int) *PressureGauge {
ch := make(chan struct{}, limit)
for i := 0; i < limit; i++ {
ch <- struct{}{}
}
return &PressureGauge{
ch: ch,
}
}
func (pg *PressureGauge) Process(f func()) error {
select {
case <-pg.ch:
f()
pg.ch <- struct{}{}
return nil
default:
return errors.New("no more capacity")
}
}
上面的PressureGauge中的ch,就可以理解为通行证。
我们一开始,在ch中塞了limit个通行证,接下来,当我们想要调用process方法,执行耗时的f函数时,我们首先,需要从ch中取得一个通行证,
如果通行证被用光了,那么就需要返回一个error,即no more capacity。
如果拿到了通行证,执行完耗时的f函数之后,需要将通行证,再返回给ch
调用方法如下:
package main
import (
"errors"
"fmt"
"time"
)
func main() {
pg := New(3)
for i := 0; i < 10; i++ {
go func() {
err := pg.Process(func() {
doThingShouldBeLimited()
})
if err != nil {
fmt.Println("To many requests")
}
}()
}
time.Sleep(20 * time.Second)
fmt.Println("-------main---------")
}
func doThingShouldBeLimited() string {
time.Sleep(2 * time.Second)
return "done"
}
执行结果:
To many requests
To many requests
To many requests
To many requests
To many requests
To many requests
To many requests
-------main---------
Process finished with the exit code 0
Turning Off a case In a select
combine data from multiple concurrent sources, the select keyword is great.
存在一个问题:
However, there are If one of the cases in a select is reading a closed channel, it will always be successful, returning the zero value.
Every time that case is selected, you need to check to make sure that the value is valid and skip the case.
If reads are spaced out, your program is going to waste a lot of time reading junk values
解决办法:
When you detect that a channel has been closed, set the channel’s variable to nil.
The associated case will no longer run, because the read from the nil channel never returns a value.
func aaa() {
in := make(chan int)
in2 := make(chan int)
done := make(chan struct{})
// in and in2 are channels, done is a done channel.
for {
select {
case v, ok := <-in:
if !ok {
in = nil
// the case will never succeed again!
continue
}
// process the v that was read from in
case v, ok := <-in2:
if !ok {
in2 = nil
// the case will never succeed again!
continue
}
// process the v that was read from in2
case <-done:
return
}
}
}
How to Time Out Code
构建一个简易的超时工具
Any time you need to limit how long an operation takes in Go, you’ll see a variation on this pattern.
We have a select choosing between two cases.
The first case takes advantage of the done channel pattern we saw earlier.
We use the goroutine closure to assign values to result and err and to close the done channel.
If the done channel closes first, the read from done succeeds and the values are returned.
The second channel is returned by the After function in the time package.
It has a value written to it after the specified time.Duration has passed. (We’ll talk more about the time package in “time”)
When this value is read before doSomeWork finishes, timeLimit returns the timeout error.
func timeLimit() (int, error) {
var result int
var err error
done := make(chan struct{})
go func() {
result, err = doSomeWork()
close(done)
}()
select {
case <-done:
return result, err
case <-time.After(2 * time.Second):
return 0, errors.New("work timed out")
}
}
If we exit timeLimit before the goroutine finishes processing, the goroutine continues to run.
We just won’t do anything with the result that it (eventually) returns.
If you want to stop work in a goroutine when you are no longer waiting for it to complete, use context cancellation, which we’ll discuss in “Cancelation”.
WaitGroup
Sometimes one goroutine needs to wait for multiple goroutines to complete their work.
If you are waiting for a single goroutine, you can use the done channel pattern that we saw earlier.
But if you are waiting on several goroutines, you need to use a WaitGroup, which is found in the sync package in the standard library.
func main() {
var wg sync.WaitGroup
wg.Add(3)
go func() {
defer wg.Done()
doThing1()
}()
go func() {
defer wg.Done()
doThing2()
}()
go func() {
defer wg.Done()
doThing3()
}()
wg.Wait()
}
A sync.WaitGroup doesn’t need to be initialized, just declared, as its zero value is useful.
There are three methods on sync.WaitGroup:
Add, which increments the counter of goroutines to wait for,
Done, which decrements the counter and is called by a goroutine when it is finished,
and Wait,which pauses its goroutine until the counter hits zero.
Add is usually called once, with the number of goroutines that will belaunched.
Done is called within the goroutine. To ensure that it is called, even if the goroutine panics, we use a defer.
You’ll notice that we don’t explicitly pass the sync.WaitGroup. There are two reasons.
The first is that you must ensure that every place that uses a sync.WaitGroup is using the same
instance. If you pass the sync.WaitGroup to the goroutine function and don’t use a pointer, then the function has a copy and the call to Done won’t decrement the original sync.WaitGroup. By using a closure to capture the sync.WaitGroup, we are assured that every goroutine is referring to the same instance.
The second reason is design. Remember, you should keep concurrency out of your API. As we saw with channels earlier,the usual pattern is to launch a goroutine with a closure that wraps the business logic. The closure manages issues around concurrency and the function provides the algorithm.
using waitGroup implement the channel is closed once
multiple goroutines writing to the same channel, you need to make sure that the channel being written is only closed once.
Let’s see how it works in a function that processes the values in a channel concurrently, gathers the results into a slice, and returns the slice:
func processAndGather(in <-chan int, processor func(int) int, num int) []int {
out := make(chan int, num)
var wg sync.WaitGroup
wg.Add(num)
for i := 0; i < num; i++ {
go func() {
defer wg.Done()
for v := range in {
out <- processor(v)
}
}()
}
go func() {
wg.Wait()
close(out)
}()
var result []int
for v := range out {
result = append(result, v)
}
return result
}
In our example, we launch a monitoring goroutine that waits until all of the processing goroutines exit. When they do, the monitoring goroutine calls close on the output channel.
The for-range channel loop exits when out is closed and the buffer is empty. Finally, the function returns the processed values.
package main
import (
"fmt"
"sync"
"time"
)
func main() {
in := make(chan int, 10)
for i := 0; i < 10; i++ {
in <- i
}
close(in)
result:=processAndGather(in, func(i int) int {
time.Sleep(1*time.Second)
return i
},3)
fmt.Println(result)
}
执行结果
[2 0 1 4 3 5 8 6 7 9]
Running Code Exactly Once(lazy load)
type SlowComplicatedParser interface {
Parse(string) string
}
var parser SlowComplicatedParser
var once sync.Once
func Parse(dataToParse string) string {
once.Do(func() {
parser = initParser()
})
return parser.Parse(dataToParse)
}
func initParser() SlowComplicatedParser {
// do all sorts of setup and loading here
}
sometimes you want to lazy load , or call some initialization code exactly once after program launch time.
This is usually because the initialization is relatively slow and may not even be needed every time your program runs.
The sync package includes a handy type called Once that enables this functionality.
We have declared two package-level variables, parser, which is of type SlowComplicatedParser, and once, which is of type sync.Once.
Like sync.WaitGroup, we do not have to configure an instance of sync.Once (this is called making the zero value useful .).
Also like sync.WaitGroup, we must make sure not to make a copy of an instance of sync.Once, because each copy has its own state to indicate whether or not it has already been used.
Declaring a sync.Once instance inside a function is usually the wrong thing to do, as a new instance will be created on every function call and there will be no memory of previous invocations.
In our example, we want to make sure that parser is only initialized once, so we set the value of parser from within a closure that’s passed to the Do method on once.
If Parse is called more than once, once.Do will not execute the closure again.
Putting Our Concurrent Tools Together
We have a function that calls three web services.
We send data to two of those services, and then take the results of those two calls and send them to the third, returning the result.
The entire process must take less than 50 milliseconds, or an error is returned.
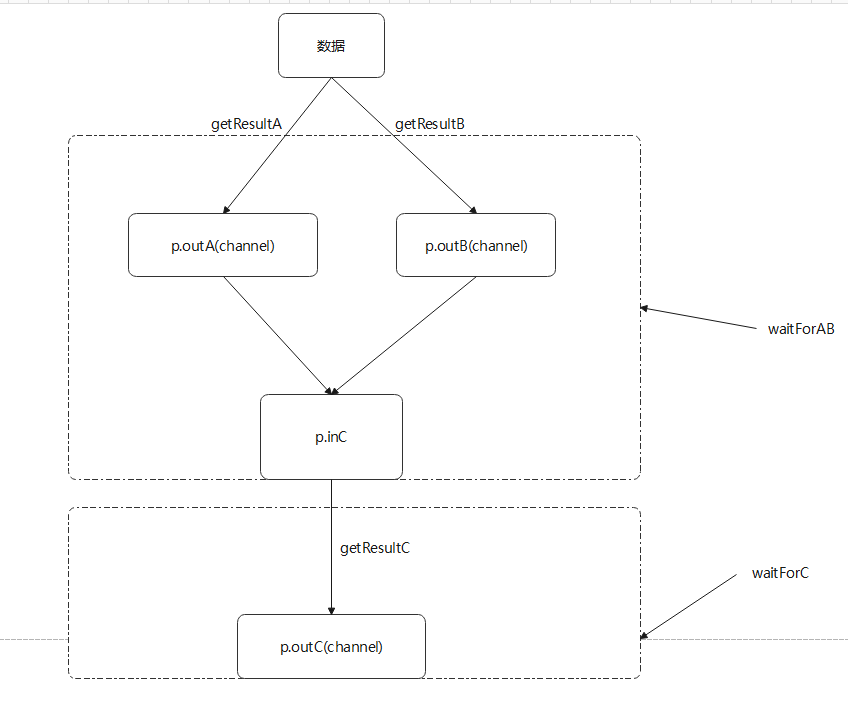
package main
import (
"context"
"fmt"
"time"
)
func main() {
ctx := context.Background()
result, err := GatherAndProcess(ctx, 3)
if err != nil {
fmt.Println(err)
}
fmt.Println(result)
}
func GatherAndProcess(ctx context.Context, data int) (int, error) {
ctx, cancel := context.WithTimeout(ctx, 5*time.Second)
defer cancel()
p := processor{
outA: make(chan int, 1),
outB: make(chan int, 1),
inC: make(chan Adder, 1),
outC: make(chan int, 1),
errs: make(chan error, 2),
}
p.launch(ctx, data)
inputC, err := p.waitForAB(ctx)
if err != nil {
return 0, err
}
p.inC <- inputC
out, err := p.waitForC(ctx)
return out, err
}
type processor struct {
outA chan int
outB chan int
outC chan int
inC chan Adder
errs chan error
}
type Adder struct {
first int
second int
}
func (p *processor) launch(ctx context.Context, data int) {
go func() {
aOut, err := getResultA(ctx, data)
if err != nil {
p.errs <- err
return
}
p.outA <- aOut
}()
go func() {
bOut, err := getResultB(ctx, data)
if err != nil {
p.errs <- err
return
}
p.outB <- bOut
}()
go func() {
select {
case <-ctx.Done():
return
case inputC := <-p.inC:
cOut, err := getResultC(ctx, inputC)
if err != nil {
p.errs <- err
return
}
p.outC <- cOut
}
}()
}
func getResultA(ctx context.Context, data int) (int, error) {
time.Sleep(1 * time.Second)
return data + 10, nil
}
func getResultB(ctx context.Context, data int) (int, error) {
time.Sleep(2 * time.Second)
return data + 100, nil
}
func getResultC(ctx context.Context, adder Adder) (int, error) {
time.Sleep(1 * time.Second)
return adder.first + adder.second, nil
}
func (p *processor) waitForAB(ctx context.Context) (Adder, error) {
var adder Adder
count := 0
for count < 2 {
select {
case a := <-p.outA:
adder.first = a
count++
case b := <-p.outB:
adder.second = b
count++
case err := <-p.errs:
return Adder{}, err
case <-ctx.Done():
return Adder{}, ctx.Err()
}
}
return adder, nil
}
func (p *processor) waitForC(ctx context.Context) (int, error) {
select {
case out := <-p.outC:
return out, nil
case err := <-p.errs:
return 0, err
case <-ctx.Done():
return 0, ctx.Err()
}
}
执行结果如下:
116
怎么实现的wait效果呢?
就是,在指定channel中读取值,如果读取不到值,那么就代表之前的步骤,还没有给出处理结果,那么读取就会处于block状态。
当能够在指定channel中读到值,读取不再处于block状态,那么就代表wait结束了。
The first thing we do is set up a context that times out in 50 milliseconds.
When there’s a context available, use its timer support rather than calling time.After.
One of the advantages of using the context’s timer is that it allows us to respect timeouts that are set by the functions that called this function.
We talk about the context in Chapter 12 and cover using timeouts in detail in “Timers”.
For now, all you need to know is that reaching the timeout cancels the context.
The Done method on the context returns a channel that returns a value when the context is cancelled, either by timing out or by calling the context’s cancel method explicitly.
After we create the context, we use a defer to make sure the context’s cancel function is called.
As we’ll discuss in “Cancelation”, you must call this function or resources leak.
We then populate a processor instance with a series of channels that we’ll use to communicate with our goroutines.
Every channel is buffered, so that the goroutines that write to them can exit after writing without waiting for a read to happen. (The errs channel has a buffer size of two, because it could potentially have two errors written to it.)
Next, we call the launch method on processor to start three goroutines: one to call getResultA, one to call getResultB, and one to call getResultC:
The goroutines for getResultA and getResultB are very similar.
They call their respective methods. If an error is returned, they write the error to the p.errs channel.
If a valid value is returned, they write the value to their channels ( p.outA for getResultA and p.outB for getResultB+).
Since the call to getResultC only happens if the calls to getResultA and getResultB succeed and happen within 50 milliseconds, the third goroutine is slightly more complicated.
It contains a select with two cases.
The first is triggered if the context is cancelled.
The second is triggered if the data for the call to getResultC is available.
If the data is available, the function is called, and the logic is similar to the logic for our first two goroutines.
After the goroutines are launched, we call the waitForAB method on processor:
This uses a for-select loop to populate inputC, an instance of CIn , the input parameter for getResultC.
There are four cases.
The first two read from the channels written to by our first two goroutines and populate the fields in inputC.
If both of these cases execute, we exit the for-select loop and return the value of inputC and a nil error.
The second two cases handle error conditions.
If an error was written to the p.errs channel, we return the error.
If the context has been cancelled, we return an error to indicate the request is cancelled.
Back in GatherAndProcess, we perform a standard nil check on the error.
If all is well, we write the inputC value to the p.inC channel and then call the waitForC method on processor:
This method consists of a single select.
If getResultC completed successfully, we read its output from the p.outC channel and return it.
If getResultC returned an error, we read the error from the p.errs channel and return it.
Finally, if the context has been cancelled, we return an error to indicate the context was cancelled.
After waitForC completes, GatherAndProcess returns the result to its caller.