Concept
文件状态
在Git中文件大概分为三种状态:已修改(modified)、已暂存(staged)、已提交(committed)
- 修改:Git可以感知到工作目录中哪些文件被修改了,然后把修改的文件加入到modified区域
- 暂存:通过add命令将工作目录中修改的文件提交到暂存区,等候被commit
- 提交:将暂存区文件commit至Git目录中永久保存
commit节点 & hash
为了便于表述,本篇文章我会通过节点代称commit提交
在Git中每次提交都会生成一个节点,而每个节点都会有一个哈希值作为唯一标示,多次提交会形成一个线性节点链(不考虑merge的情况),如图1-1
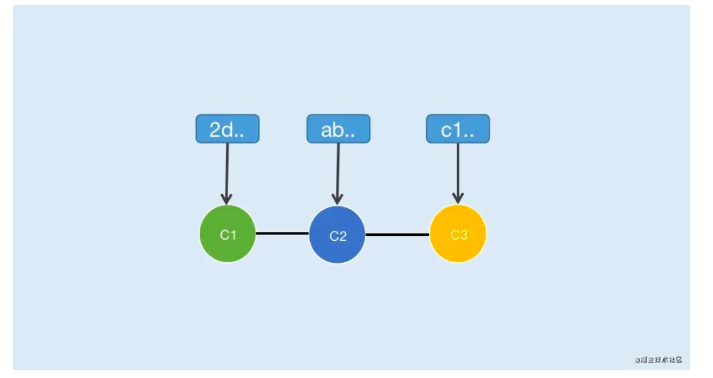
节点上方是通过 SHA1计算的哈希值
C2节点包含C1提交内容,同样C3节点包含C1、C2提交内容
HEAD
HEAD是Git中非常重要的一个概念,你可以称它为指针或者引用,它可以指向任意一个节点,并且指向的节点始终为当前工作目录,换句话说就是当前工作目录(也就是你所看到的代码)就是HEAD指向的节点。
还以图1-1举例,如果HEAD指向C2那工作目录对应的就是C2节点。具体如何移动HEAD指向后面会讲到,此处不要纠结。
同时HEAD也可以指向一个分支,间接指向分支所指向的节点。
分支
分支也是Git中相当重要的一个概念,当一个分支指向一个节点时,当前节点的内容即是该分支的内容,它的概念和HEAD非常接近同样也可以视为指针或引用,不同的是分支可以存在多个,而HEAD只有一个。通常会根据功能或版本建立不同的分支。
我们可以这样理解:
每次commit,我们都认为照了一张快照A,这个快照肯定是包含了所有的之前commit内容,然后如果是拉取分支,其实新的分支就是指向这个快照A,类似于java中的引用指向实际对象一样,这里分支就是一个引用,而快照A就是实际对象。
那如果,我们在新的分支上,修改了一些代码,然后这些代码commit,其实就是相当于在快照A的基础上,修改了一些东西,然后生成了新的快照B
那分支有什么用呢?
- 举个例子:你们的 App 经历了千辛万苦终于发布了v1.0版本,由于需求紧急v1.0上线之后便马不停蹄的开始v1.1,正当你开发的兴起时,QA同学说用户反馈了一些bug,需要修复然后重新发版,修复v1.0肯定要基于v1.0的代码,可是你已经开发了一部分v1.1了,此时怎么搞?
面对上面的问题通过引入分支概念便可优雅的解决,如图2-1
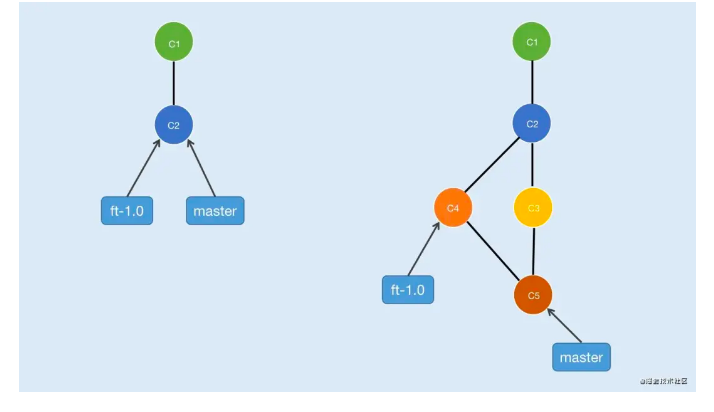
- 先看左边示意图,假设C2节点既是v1.0版本代码,上线后在C2的基础上新建一个分支ft-1.0
- 再看右边示意图,在v1.0上线后可在master分支开发v1.1内容,收到QA同学反馈后提交v1.1代码生成节点C3,随后切换到ft-1.0分支做bug修复,修复完成后提交代码生成节点C4,然后再切换到master分支并合并ft-1.0分支,到此我们就解决了上面提出的问题
除此之外利用分支还可以做很多事情,比如现在有一个需求不确定要不要上线,但是得先做,此时可以单独创建一个分支开发该功能,等到啥时候需要上线直接合并到主分支即可。
分支适用的场景很多就不一一列举了。
注意:
当在某个节点创建一个分支后,并不会把该节点对应的代码复制一份出来,只是将新分支指向该节点,因此可以很大程度减少空间上的开销。一定要记着不管是HEAD还是分支它们都只是引用而已,量级非常轻
reset & 3个工作区
git 有3个区域:工作区、暂存区,还是版本库
git reset有三个选项,–hard、–mixed、–soft。
# 仅仅只是撤销已提交的版本库,不会修改暂存区和工作区
git reset --soft 版本库ID
# git reset 默认选项就是mixed
# 仅仅只是撤销已提交的版本库和暂存区,不会修改工作区
git reset --mixed 版本库ID
# 彻底将工作区、暂存区和版本库记录恢复到指定的版本库
git reset --hard 版本库ID
那我们到底应该用哪个选项好呢?
为了防止,文件出现错乱,我们一般都直接使用reset --hard,来将代码,恢复到指定版本
基础操作
提交相关
前面我们提到过,想要对代码进行提交必须得先加入到暂存区,Git中是通过命令 add 实现
添加某个文件到暂存区:
git add 文件路径
添加所有文件到暂存区:
git add .
同时Git也提供了撤销工作区和暂存区命令
撤销工作区改动:
# git checkout -- 文件名
git checkout iot-manage/src/main/java/com/iot/controller/TMqttClientController.java
# 撤销工作区中所有内容
git checkout .
提交:
将改动文件加入到暂存区后就可以进行提交了,提交后会生成一个新的提交节点,具体命令如下:
git commit -a -m "该节点的描述信息"
分支的增删改查
基于远程dev分支,创建一个本地分支dev_weipeng,并且切换到这个新创建的本地分支dev_weipeng
git checkout -b dev_weipeng remotes/origin/dev
切换到一个已存在的分支。
当切换分支后,默认情况下HEAD会指向当前分支,即HEAD间接指向当前分支指向的节点
git checkout 分支名
查询
# 查看远程分支
$ git branch -a
* master
remotes/origin/dev
remotes/origin/test
# 查看本地分支
$ git branch
* dev_weipeng
master
# 查看本地分支 和 远程分支的 绑定关系
$ git branch -vv
* dev_weipeng 684a938 [origin/dev] 卫鹏---删除客户端,增加级联判断
master 4bb35bc [origin/master] Merge branch 'dev
删除一个分支
git branch -d 分支名
merge & rebase & cherry-pick
merge
merge是最常用的合并命令,它可以将某个分支或者某个节点的代码合并至当前分支。具体命令如下:
git merge 分支名/节点哈希值
# 当前分支:master
# 这个表示,将feature分支的代码,合并到当前分支---master,
# 也就是说,master分支被更新了,但是feature分支代码,没有变化
git merge feature
如果需要合并的分支完全领先于当前分支,如图3-1所示
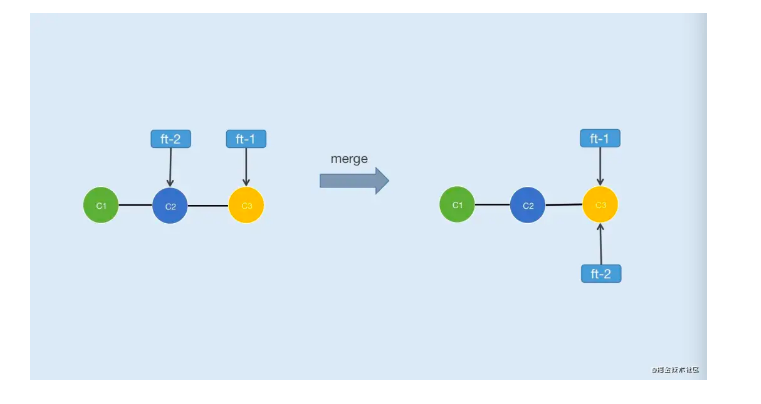
由于分支ft-1完全领先分支ft-2即ft-1完全包含ft-2,所以ft-2执行了“git merge ft-1”后会触发fast forward(快速合并),此时两个分支指向同一节点,这是最理想的状态。
但是实际开发中我们往往碰到是是下面这种情况:如图3-2(左)
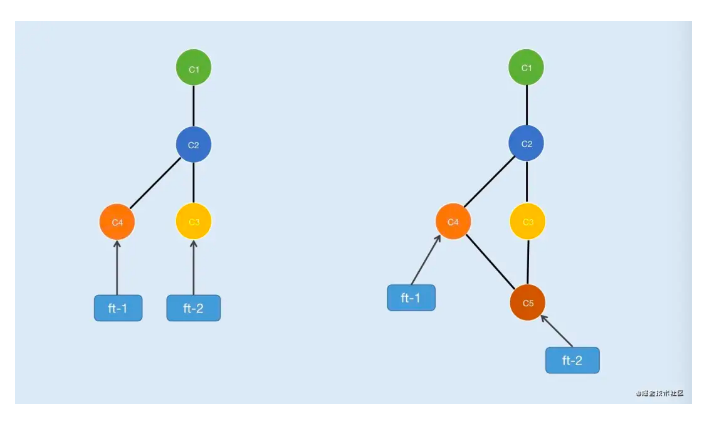
这种情况就不能直接合了,当ft-2执行了“git merge ft-1”后Git会将节点C3、C4合并随后生成一个新节点C5,最后将ft-2指向C5 如图3-2(右)
注意点:
如果C3、C4同时修改了同一个文件中的同一句代码,这个时候合并会出错,因为Git不知道该以哪个节点为标准,所以这个时候需要我们自己手动合并代码
rebase
首先说说rebase的功能,rebase的功能说白了可以提取我们在A分支上的改动,然后应用在B分支的代码上,完成类似于补丁的功能。
我这么说非常空洞,我从learngitbranching.js.org网站上截取了一些图,会清晰一些。另外推荐一下这个网站,当中有一些图形化的演示和实操功能, 我们可以在上面练习我们学到的git命令加深印象。但是它也有一个缺点,就是一些细节介绍得比较少,这也是我没有一开始的时候就推荐给大家的原因。
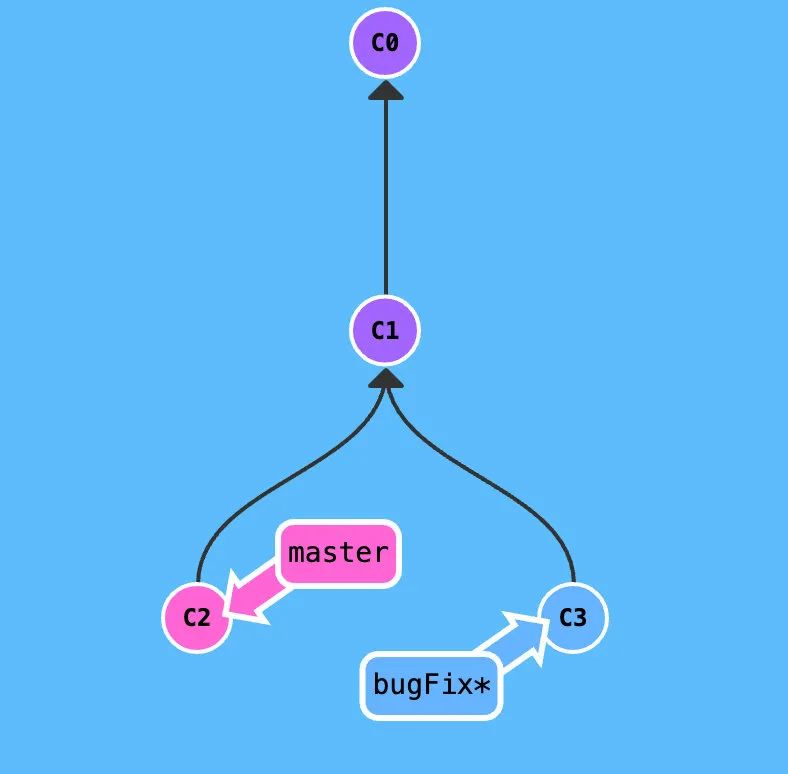
这张图非常经典,是很多场景下的常态。C1是线上的版本,在C1的代码上线了之后我们发现了一个bug,于是我们checkout了一个叫做bugFix的分支。与此同时还有新的功能在开发,新的功能提交到了master之后形成了节点C2。
这个时候我们在bugFix分支当然可以merge master这没有什么问题,但是也可以rebase master,rebase之后整棵git树会变成这样:
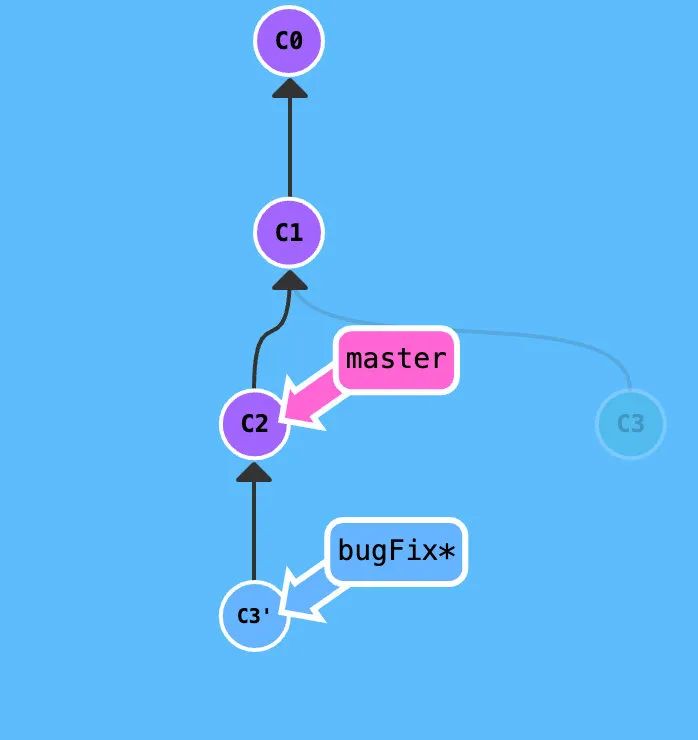
这个结果就好像是我们先到了C2然后checkout出了bugFix分支,然后在bugFix分支上将之前写过的代码重新写了一遍。这样的操作就是变基。
当我们rebase了之后再提交合并请求我们的合并记录里面会非常干净,没有多余merge的信息。对于多人协同开发的场景非常有帮助。
上面就是变基的形象展示,将地基从c1改成了c2,rebase master,含义就是将master作为新的地基,然后比较c3与master,找出有差异的代码,然后将c3中将有差别的代码,提取出来,在master的基础上,重新提交进去。提交后叫c3’
提交完成后,会将原来的c3节点丢掉,然后复制c3’ 节点,复制后的名字又命名为c3节点
rebase相比于merge提交历史更加线性、干净,使并行的开发流程看起来像串行,更符合我们的直觉。既然rebase这么好用是不是可以抛弃merge了?其实也不是了,下面我罗列一些merge和rebase的优缺点:
merge优缺点:
- 优点:每个节点都是严格按照时间排列。当合并发生冲突时,只需要解决两个分支所指向的节点的冲突即可
- 缺点:合并两个分支时大概率会生成新的节点并分叉,久而久之提交历史会变成一团乱麻
rebase优缺点:
- 优点:会使提交历史看起来更加线性、干净
- 缺点:虽然提交看起来像是线性的,但并不是真正的按时间排序,比如图3-3中,不管C4早于或者晚于C3提交它最终都会放在C3后面。并且当合并发生冲突时,理论上来讲有几个节点rebase到目标分支就可能处理几次冲突
rebase的作用就是:重新构建项目历史,可以理解为穿越到古代【baseBranch】,重新创建历史。
# 当前分支:feature
git rebase [baseBranch]
# 这个表示,以master为基石,重新构建项目历史,将feature修改的代码,回放下,然后得到最新的feature分支代码。这样就将master分支的代码,也合并到feature上了
git rebase master
# 这里,就是穿越到master分支,然后,重新创建feature分支的历史
我们在,从远程仓库,拉取最新代码,有2种方式:一种是pull,一种是fetch + rebase。
这里,我们分别看下
# 表示,拉取远程的dev分支代码,并合并到本地的dev_weipeng分支上
# git pull <远程主机名> <远程分支名>:<本地分支名>
git pull origin dev:dev_weipeng
# 当前本地分支是dev_weipeng
# 以下两步是,拉取远程的dev分支代码,并且以远程dev分支为基,将本地dev_weipeng分支上的代码,重写一遍
git fetch origin dev
git rebase origin/dev
rebase临时文件
在执行rebase命令时,
会产生一个临时的 rebase 描述文件,并进入 vim 编辑器,我们需要编译这个文件,告诉 git 要如何 rebase。
文件开头每一行是对一次 commit 的 rebase 描述,根据下方的提示修改各行描述信息。每行描述有三段,命令、commitId、commitMessage
其中主要的命令有如下几个:
| 命令 | 提交(修改)内容 | 提交记录 | 提交信息(commit message) |
|---|---|---|---|
| p | 保留 | 保留 | 保留 |
| s | 保留 | 不保留 | 不保留,但是将本次commit message添加到上个提交的后边 |
| f | 保留 | 不保留 | 不保留 |
| d | 不保留 | 不保留 | 不保留 |
pick 保留提交记录,每出现一个 p,rebase完成之后,会有一行提交记录。rebase不一定会把所有提交合并为一,而是出现几个p,合并为几个提交记录。
squash 会保留这次提交所作的修改,但不保留提交记录,会把这次修改压缩合并到上个提交,就是上面的pick记录上,同时将本次commit message添加到上个提交的后边。
fixup 与 squash 类似,会把这次修改压缩合并到上个提交,但是不添加commit message。
drop 会彻底丢弃这次提交,就像从来没有过这次提交一样,rebase完成之后,这条提交记录没有了,它所做的修改也没有了。
merge 冲突 和 rebase 冲突
merge解决冲突
解决冲突后,要用git add commit 后产生一个新的提交
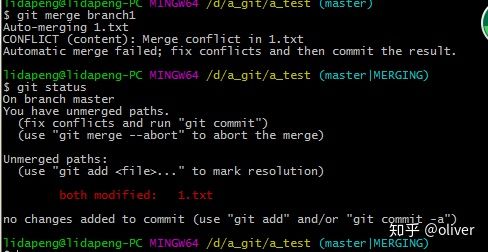
冲突后,git status
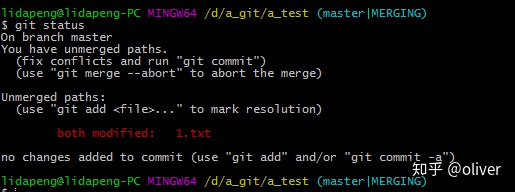
解决冲突后
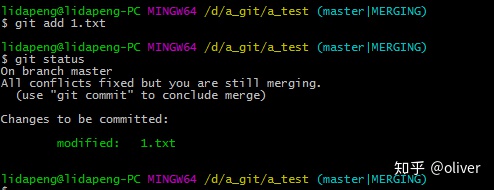
git add 后提示还在merging
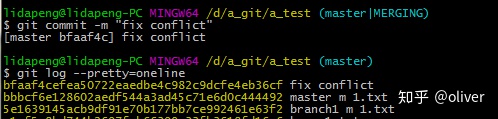
git commi后,产生一个新的提交
rebase解决冲突
git rebase的作用是,将HEAD指向将要合并过来的分支,然后将本地分支的提交作为补丁,分别应用到HEAD上,有冲突解决冲突,然后Git add后执行git rebase --continue.继续其他补丁。
git rebase由冲突后,fix后,需要执行 git add标记冲突已解决。 记住:Git是根据index生成tree和commit对象的。
git rebase不需要git commit, 因为git rebase的过程中就会自动生成新的commit对象。
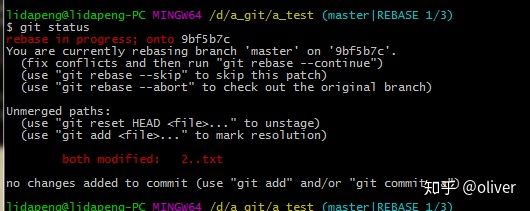
解决冲突后,git status.
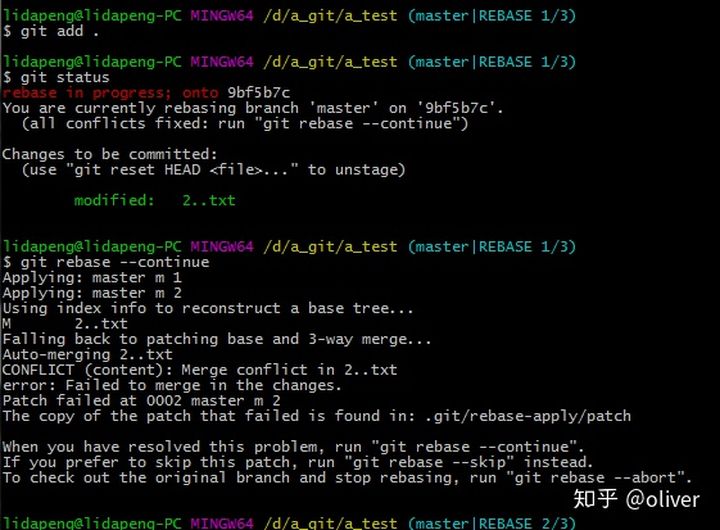
加入index后,继续 rebase其他补丁
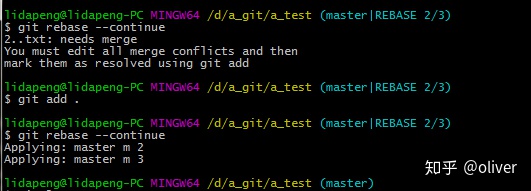
继续其他补丁
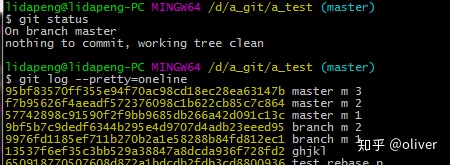
最后的结果